KBCollectionHighlights
| << Back to index of this story | >> To the Github repo of this page |

50 cool new things you can now do with KB’s collection highlights - Part 6, Summary
Latest update 16-06-2021

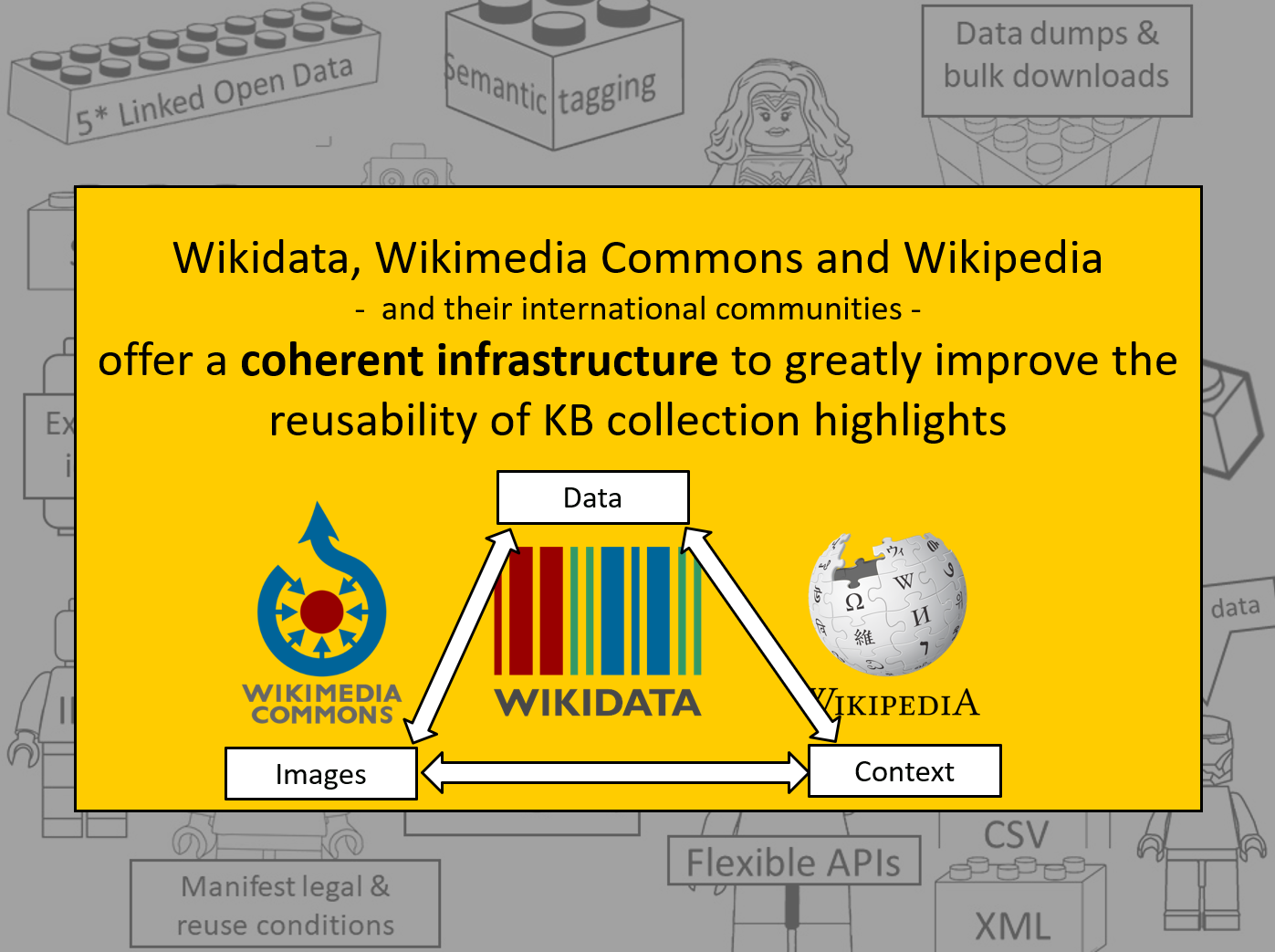
In this series of 5 articles I show the added value of putting images and metadata of digitised collection highlights of the KB, national library of the Netherlands, into the Wikimedia infrastructure. By putting our collection highlights into Wikidata, Wikimedia Commons and Wikipedia, dozens of new functionalities have been added. As a result of Wikifying this collection, you can now do things with these highlights that were not possible before.
As a bonus - and for overview - I’ve created a summary of the individual summaries from parts 2, 3, 4 and 5. This 6th part summarizes all 50 new cool things in one super handy single list.
Part 1, Introduction
In the introduction of the series I discussed the things (functionalities) you could already do with KB’s collection highlights on KB’s own native websites, before we started the WikiProject Collection highlights in 2020. I also looked at some of the limitations that arise from offering our highlights in read/view-only mode, catering for classical heritage consumers.
I explained why it made sense to also offer our collection highlights as LEGO®-like building blocks to creative and technical audiences, allowing them to freely and openly reuse and combine this collection as they see fit. We choose the Wikimedia infrastructure (the combination of Wikidata, Wikimedia Commons and Wikipedia) as our toolkit, as many of the building blocks we were looking for were readily available on those platforms.
A visual summary:





Part 2, Overviews of all highlights
In the second article I looked at which handy & useful overviews of all highlights combined have become available as a result of Wikifying our highlights. These include
1) A thumbnail gallery for all highlights.
2) A visual gallery page with 6 previews for each highlight.
3) An overview of highlights grouped by type/sort.
4) An alphabetical overview for all highlights, powered by Wikidata and templates.
5) A sortable overview table for all highlights.
6) Manifest copyright status for all highlights.
7) Highlights available as PDFs.
8) An interactive timeline for all highlights.
9) Overviews of persons & institutions related to the highlights, including
10) a table of related persons sortable by role.
11) Overviews of locations and dates, physical characteristics and sources for the highlights, as was well as descriptions in 3rd party databases.
12) A separate overview of existing and wanted Dutch Wikipeda articles related to KB’s collection highlights.
Part 3, Overviews per highlight
In the third article I discussed which new functionalities for individual highlights are available from now on, including
13) Merging KB’s institutional and Wikimedia’s participative worlds for each highlight.
14) A gallery page with individual images for each public domain highlight.
15) Double page openings for most public domain highlights.
16) Miniatures and/or cut-outs of interesting page sections for selected public domain highlights.
17) Openly licensed audio tracks and
18) explainer videos for selected highlights.
19) Reusable introduction texts under CC0-licensing for each highligt.
20) Openly licensed and freely reusable building blocks (images, audio, videos, texts) for each highligt.
21) A KB citation template for use on Dutch Wikipedia.
22) A facebook of contributors to the Album amicorum Jacob Heyblocq.
23) Overviews of the gender distribution,
24) the occupations and
25) the life spans of those contributors.
26) Map visualisations for selected highlights in which locations and places play key roles.
Part 4, Images
In this article I showed which new functionalities for individual highlight images are available now that they are part of the Wikimedia infrastructure. These include
27) Image downloads in various resolutions.
28) File level descriptive metadata including
29) textual and visual source attribution of the KB,
30) manifest copyrights status (public domain) and
31) multiple thematic categorisations.
32) Geo coordinates for selected images, linking them to various map services.
33) Structured, machine-readable data, linking images to Wikidata, enabling
34) ‘automatic multilinguality’ and multilingual search, and
35) making them searchable by content. (What is depicted in the images?)
36) Stimulate (inter)national participation for enriching KB’s collections by public tagging campaigns, enabling
37) new search options for these collections.
{kind=link}
.jpg¶ms=052.081352_N_0004.313528_E_globe:Earth_type:camera_source:Flickr_&language=nl){kind=link}
Part 5, Reuse
In the last article I illustrated how you can programmatically reuse KB’s collection highlights, for instance for/in your own websites, services, apps, hackathons and projects. Nice LEGO Technic® blocks for KB’s target group of developers, app builders, digital humanists, data scientists, LOD afficionados and other nice nerds. Cool stuff includes
38) A SPARQL driven thumbnail gallery of KB highlights.
39) Structured lists of all KB highlights, both simple and more elaborate in JSON and XML.
40) Programatically check for Wikipedia articles about KB highlights in Dutch.
41) Request multiple image URLs from the Wikimedia Commons query API for a specific highlight, both via URL query strings and Python scripts.
42) Readily available bulk image download tools for obtaining hires image URLs and/or the hires images themselves from a specific KB highlight category on Wikimedia Commons.
43) Request highlight information from the Wikidata API in multiple formats, directly from the highlight’s Qnumber.
44) Request full Wikidata items in seven different formats via a Special:EntityData URL, directly from the Qnumber: HTML, JSON, JSON-LD, RDF, NT, TTL or N3 and PHP.
45) Get a structured, machine readable overview of persons and institutions related to KB highlights, such as authors, makers, contributors, publishers, printers, illustrators, translators, owners, collectors etc.
46) Multiple approaches for generating off-Wiki image galleries from the Wikimedia infrastructure, as detailed in the article Reusing the album amicorum Jacob Heyblocq - Image gallery of album contributors.
47) Programmatically retrieve things depicted in images, either via the Wikimedia Commons SPARQL query service, the Wikimedia Commons API or via the Petscan tool.
48) Starting from selected Wikidata biographical identifiers such as the Europeana entity (P7704), extract information from external (non-Wikimedia) databases using their REST APIs.
49) Extract information simultaneously from both Wikidata and external databases using federated SPARQL queries, such as this example.
50) Programmatically request (meta)data associated with an individual image via both the Wikimedia Commons API tool and directly from the Commons API, using these examples and this imageinfo API documentation for inspiration.
About the author

Olaf Janssen is the Wikimedia coordinator of the KB, the national library of the Netherlands. He contributes to
Wikipedia, Wikimedia Commons and Wikidata as User:OlafJanssen
Reusing this article
This text of this article is available under the CC-BY 4.0 license.

Image sources & credits
- Swiss_army_knife_open,_2012-(01) – Joe Loong, CC BY-SA 2.0, via Wikimedia Commons
- Victorinox_Swiss_Army_SwissChamp_XAVT – Dave Taylor from Boulder, CO, CC BY 2.0, via Wikimedia Commons
- Old paradigm, Taxidermied Monarch Butterfly in a bell jar – Jeremy Johnson, CC BY-SA 4.0, via Wikimedia Commons
- New paradigm, Bricks by the Bay 2011 – Roninsfx, CC-BY 2.0, via Flickr
- Building blocks for the tech communities, Wikimedia hackathon San Francisco 2012 – Matthew (WMF), CC BY-SA 3.0, via Wikimedia Commons
- KB collection highlights LEGO® box - based upon the Villa Savoye box from the LEGO® Architecture series
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}