KBCollectionHighlights
| << Back to index of this story | >> To the Github repo of this page |

50 cool new things you can now do with KB’s collection highlights - Part 5, Reuse
Latest update 12-11-2023

In this series of 5 articles I show the added value of putting images and metadata of digitised collection highlights of the KB, national library of the Netherlands, into the Wikimedia infrastructure. By putting our collection highlights into Wikidata, Wikimedia Commons and Wikipedia, dozens of new functionalities have been added. As a result of Wikifying this collection, you can now do things with these highlights that were not possible before.
In the previous (fourth) part of this series I discussed 11 tools of the right hand knife. We looked at which new functionalities have become available for individual highlight images. We talked about the ability to download images in multiple resolutions, file level descriptive metadata with manifest attributions and copyrights status, geo coordinates linking images to various map services, linking images to Wikidata, as well as enabling multilingual search by content (What is depicted in the images?)
{kind=link}
.jpg¶ms=052.081352_N_0004.313528_E_globe:Earth_type:camera_source:Flickr_&language=nl){kind=link}
In this fifth part I am going to unfold the last group of tools. I am going to illustrate how you can programmatically reuse KB’s collection highlights, for instance for/in your own websites, services, apps, hackathons and projects. I’m going to talk about SPARQL, APIs, Python scripts, JSON, XML, image bulk downloading and machine interactions with our highlights. Cool LEGO Technic® blocks for KB’s target group of developers, app builders, digital humanists, data scientists, LOD afficionados and other nice nerds.


I’ll try to follow the same order as in Part 2 , 3 and 4, so
- all highlights together (38-40)
- indivudual highlights (41-49)
- individual highlight images (50).
I’ll illustrate how you can retrieve the same images, data and texts we requested via the GUI (so in HTML) in these previous parts, but now in their raw, machine readable formats (JSON, XML etc.) using Wikimedia’s APIs and SPARQL services. This will give you more control & flexibilty over the exact outputs, custom made for your needs.
Reuse - all highlights
38) SPARQL driven thumbnail gallery of KB highlights
Let’s start with recreating the image grid we started out with in Part 2 using the Wikidata SPARQL query service. A short SPARQL query does the job:
# Thumbnail gallery of KB collection highlights
#defaultView:ImageGrid
SELECT DISTINCT ?item ?itemLabel ?image WHERE {
# the thing is part of the KB collection, and has role 'collection highlight' within that collection
?item (p:P195/ps:P195) wd:Q1526131; p:P195 [pq:P2868 wd:Q29188408].
OPTIONAL{?item wdt:P18 ?image.}
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
} ORDER BY ?itemLabel
This query results into a SPARQL driven thumbnail gallery of KB highlights.
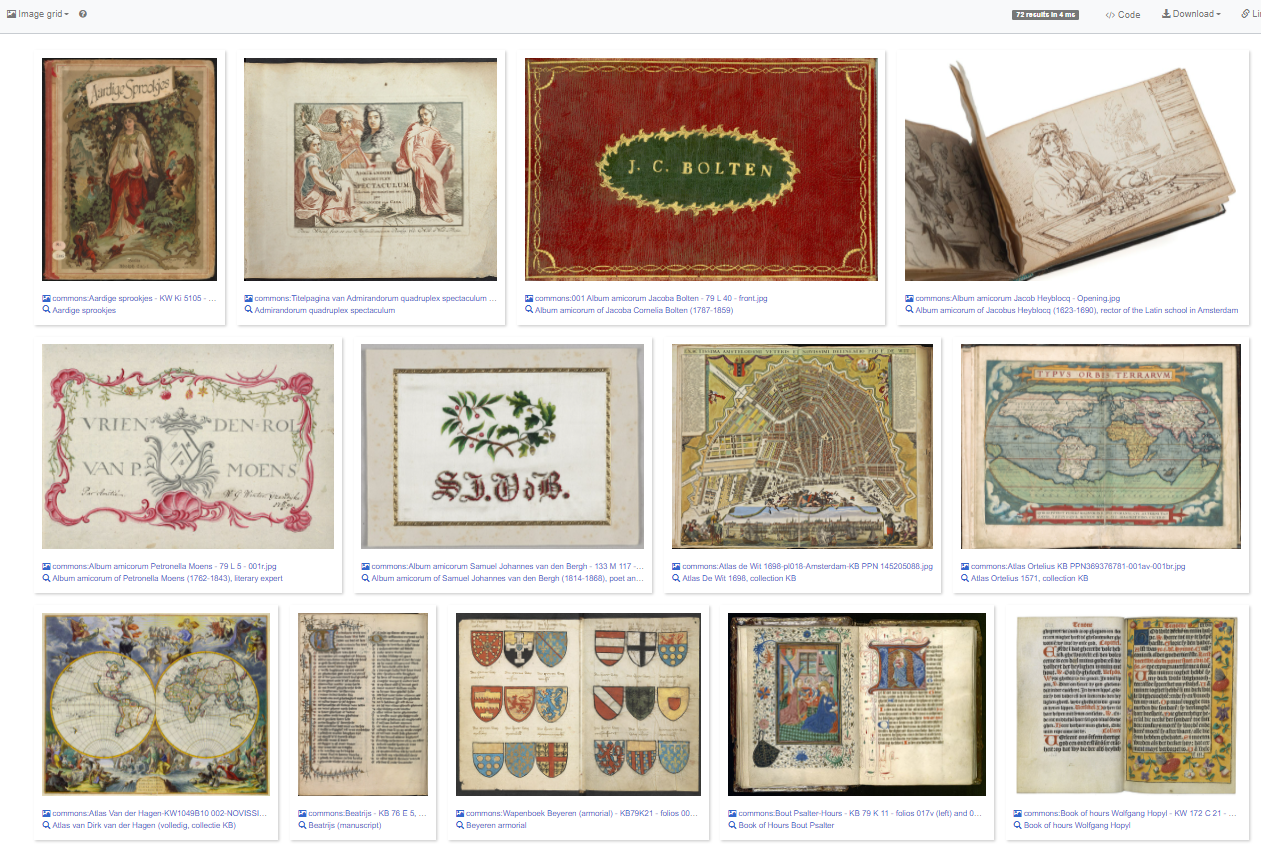
The image grid of KB highlights for the above SPARQL query. Screenshot Wikidata query service d.d. 23-04-2021
39) Structured lists of all KB highlights, both simple and in JSON and XML
Next, let’s look at lists and tables. The list of highlights on the KB website is only availabe as HTML. For effective reuse you’d prefer it in a structured and open format such as JSON, XML or RDF. Let’s look how we can request structured lists of KB highlights, both simple and more elaborate from the Wikidata query service:
- Simple list, using this query:
# Simple list of KB collection highlights SELECT DISTINCT ?highlight ?highlightLabel ?highlightDescription WHERE { # the thing is part of the KB collection, and has role 'collection highlight' within that collection ?highlight (p:P195/ps:P195) wd:Q1526131; p:P195 [pq:P2868 wd:Q29188408]. SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } } ORDER BY ?highlightLabelIt results into a simple list of KB collection highlights, with the names, labels and descriptions in English.
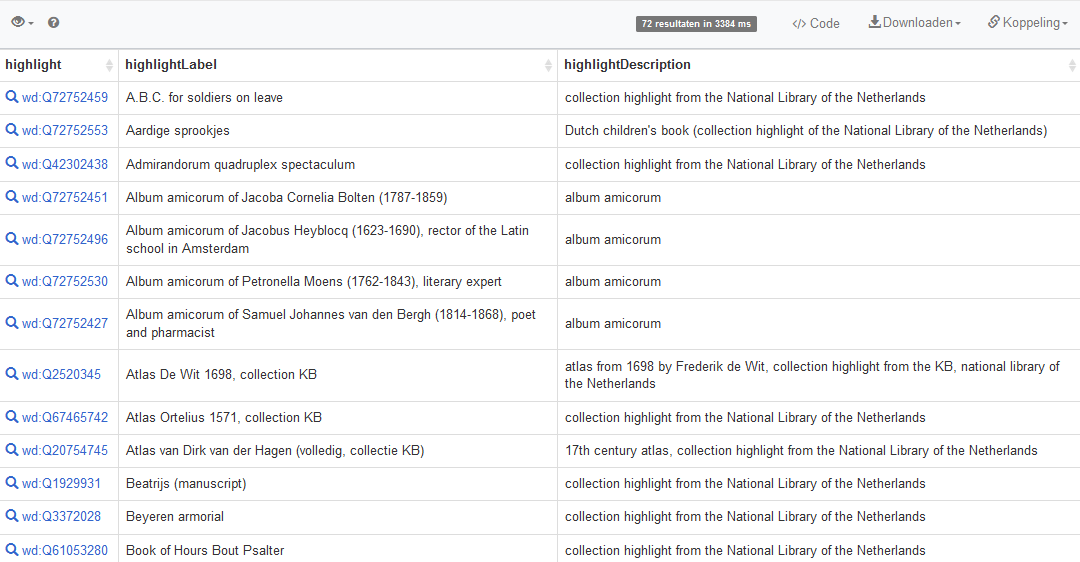
Result of the query, a simple list of KB collection highlights, with the names, labels and descriptions in English. Screenshots Wikidata query service d.d. 28-04-2021You can request the result as JSON and as an XML download as well.
-
Elaborate list, recreating the overview table of KB collection highlights from Part 2 via this SPARQL query:
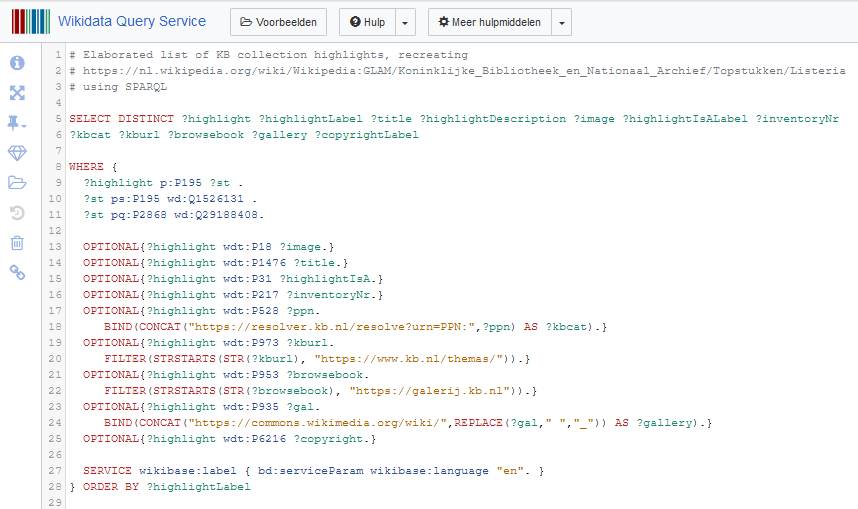
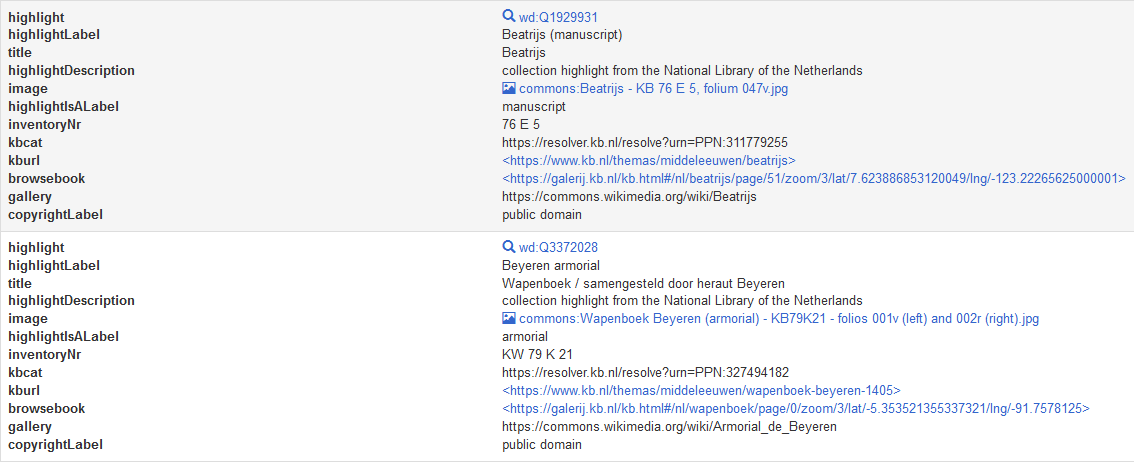
Left: SPARQL query to create an elaborate list of KB collection highlights. Right: Result of the query, an elaborate list of KB collection highlights. Please note the results have not been aggregated by the GROUP_CONCAT function, hence the higher number of results compared to the simple query. Screenshots Wikidata query service d.d. 28-04-2021You can also request the result as JSON and as an XML download.


Left: JSON result of the query. Right: XML result of the query. Screenshots Wikidata query service d.d. 28-04-2021
40) Programatically check for Wikipedia articles about KB highlights in Dutch
You might want to programatically check for Wikipedia articles about KB highlights, for instance in Dutch, using this query:
#Articles about KB collection highlights on Dutch Wikipedia
select ?item ?itemLabel ?articleNL where {
?item (p:P195/ps:P195) wd:Q1526131; p:P195 [pq:P2868 wd:Q29188408].
OPTIONAL {
?articleNL schema:about ?item.
?articleNL schema:isPartOf <https://nl.wikipedia.org/>.
}
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en,nl". }
}
As before, the results can be requested in JSON and in XML as well.
Reuse - individual highlights
41) Request multiple image URLs from the Wikimedia Commons query API for a specific highlight
In Part 3 we looked at individual pages (14), double page openings (15) and miniatures/page details (16) that are available for public domain highlights. Let’s see how we can request image URLs from the Wikimedia Commons query API using this documentation.
- Individual pages
For Armorial de Beyeren we can request a simple list of images- in JSON: https://commons.wikimedia.org/w/api.php?action=query&generator=categorymembers&gcmlimit=500&gcmtitle=Category:Armorial%20de%20Beyeren&format=json&gcmnamespace=6 and
- in XML: https://commons.wikimedia.org/w/api.php?action=query&generator=categorymembers&gcmlimit=500&gcmtitle=Category:Armorial%20de%20Beyeren&format=xml&gcmnamespace=6.
Here we are filtering on namespace=6 (ns=6), so we are looking for files only (ie. no categories (ns=14) or galleries (ns=0)).
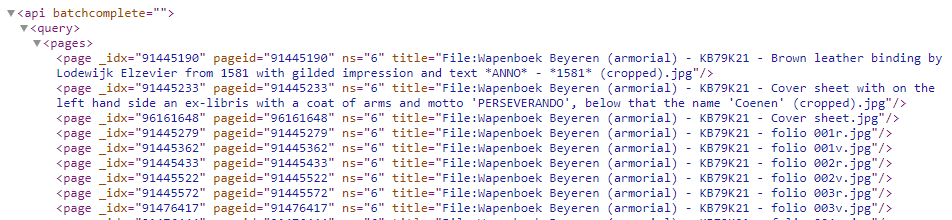
XML list of files from Armorial de Beyeren using this API call. Screenshot Wikimedia Commons API, d.d. 29-04-2021 -
Double page openings
The downside of the above reponses is that they do not contain URLs (starting with https://), but only Wikimedia Commons file names. To request https URLs we need to modify our API call. When we apply the modified call to the double page openings of Visboek Coenen,we get this XML reponse
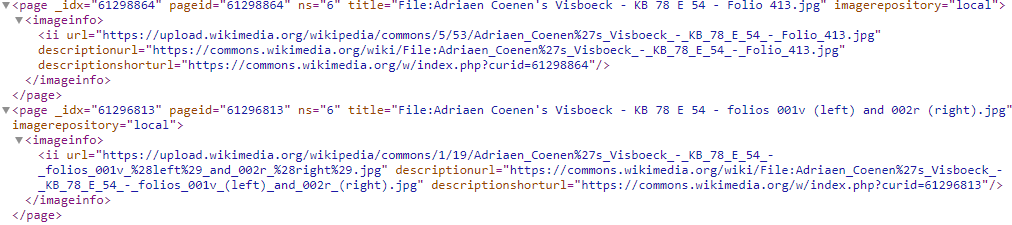
XML reponse containing https URLs to the double page openings of Visboek Coenen using this API call. Screenshot Wikimedia Commons API, d.d. 29-04-2021Please note that this reponse contains both direct download URLs of the hires images (example), as well as two forms of URLs of the Wikimedia Commons files page (example).
- Miniatures and page details
Besides calling the API by a URL query string (as done above), it is also possible to do this via a Python script. For instance, we can request the miniatures from Chroniques de Froissart:
{kind=link}
{kind=link}
#!/usr/bin/python3
import requests, json
S = requests.Session()
URL = "https://commons.wikimedia.org/w/api.php"
PARAMS = {
"action": "query",
"gcmtitle":"Category:Chroniques_de_Froissart,_vol_1_-_Den_Haag,_KB_:_72_A_25_(details)",
"gcmlimit":"500",
"generator":"categorymembers",
"format":"json",
"gcmtype":"file",
"prop":"imageinfo",
"iiprop":"url"
}
R = S.get(url=URL, params=PARAMS)
DATA = R.json()
PAGES = DATA['query']['pages']
print(json.dumps(PAGES, indent=2))
Running this script in my Python IDE gives the following output:
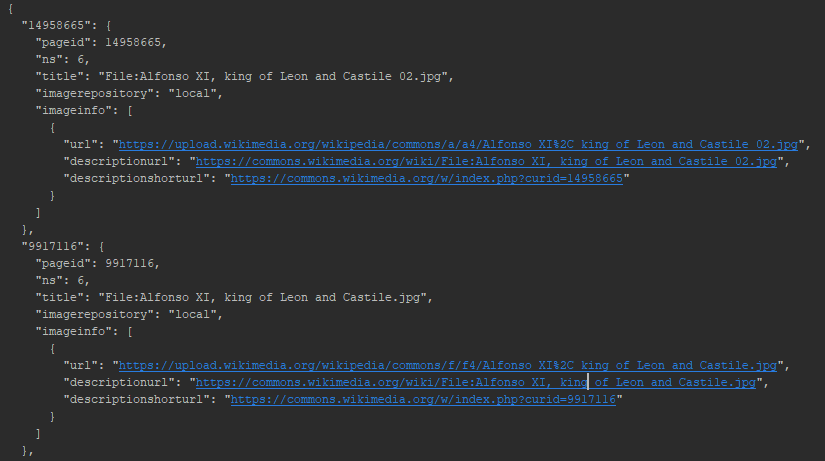
Titles and URLs of miniatures from Chroniques de Froissart formatted as JSON. Screenshot Pycharm IDE, d.d. 29-04-2021
42) Readily available bulk image download tools
If you don’t want to use the Wikimedia Commons API for getting image URLs, no problem, there a some readily available bulk image download tools for obtaining the hires image URLs and/or the hires images themselves from a specific KB highlight category on Wikimedia Commons.
Using the Wiki Loves Downloads tool you can easily get all the direct download URLs of the hires images of eg. the Reward letter of King Filip II of Spain to family of Balthasar Gerards, 1590. Because this tool was developed by Wikimedia Deutschland, the default user interface is in German. We can use Google Translate to get a English user interface for international audiences. As stated in the tool, it divides the images of a category from Wikimedia Commons into a desired number of lists and generates these in the form of (zipped) text files with links to the respective images so that they can be downloaded with the help of a download manager (or a script).
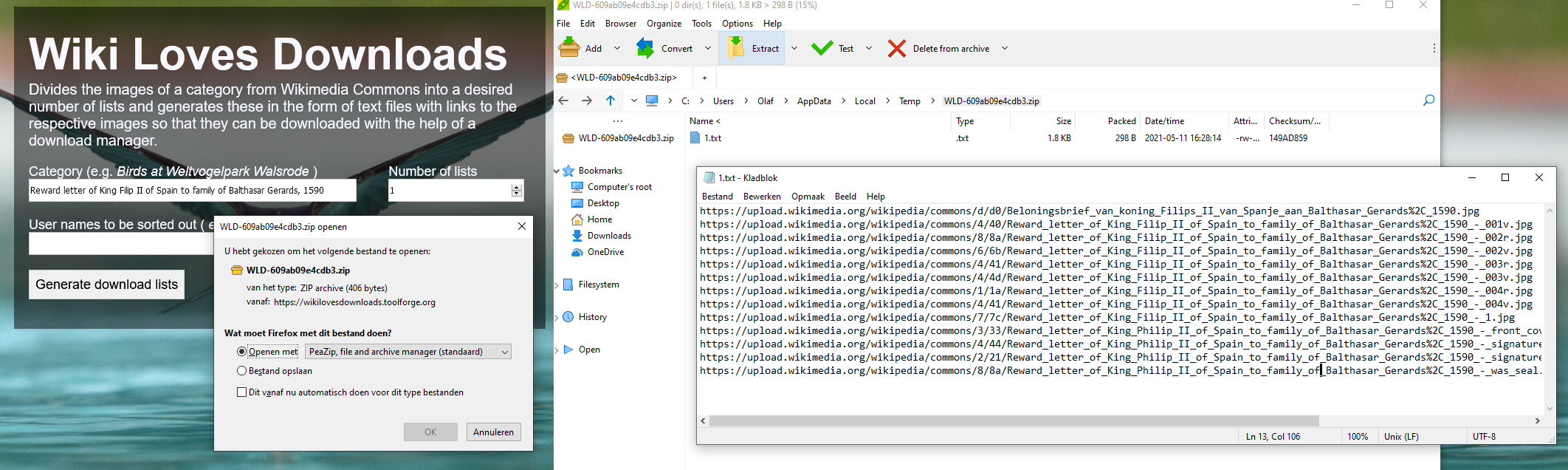
Getting the direct download URLs of the hires images of the Reward letter of King Filip II of Spain to family of Balthasar Gerards, 1590. Screenshot Wiki Loves Downloads with translated English user interface, d.d. 11-05-2021
If you prefer the images themselves rather than only the URLs, the Java based Imker tool is the way to go. It downloads all images from a specific category (or page) on Wikimedia Commons (or any other Wikimedia site) to your local machine.
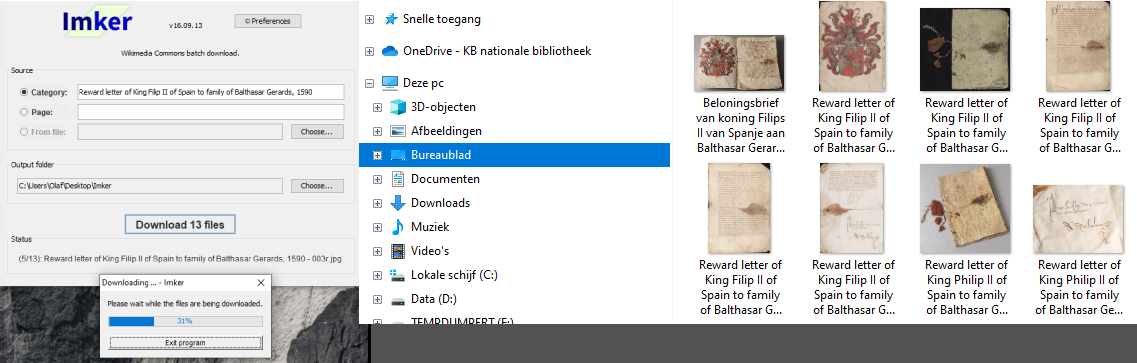
Downloading the hires images of the Reward letter of King Filip II of Spain to family of Balthasar Gerards, 1590. Screenshot of the Imker tool, d.d. 11-05-2021
43) Request highlight information from the Wikidata API, directly from the highlight’s Qnumber.
Every KB highlight is described by a Wikidata item (Qnumber). Let’s see how we can request highlight information from the Wikidata API directly from that Qnumber. We can use the wbgetentities action for that.
-
Get all information (‘the entire Qnumber’) from the Beatrijs manuscript (Q1929931) in all available languages, as JSON: https://www.wikidata.org/w/api.php?action=wbgetentities&ids=Q1929931
-
Get only the labels of the Egmond Gospels (Q759256) in all available languages, as XML: https://www.wikidata.org/w/api.php?action=wbgetentities&ids=Q759256&props=labels&format=xml
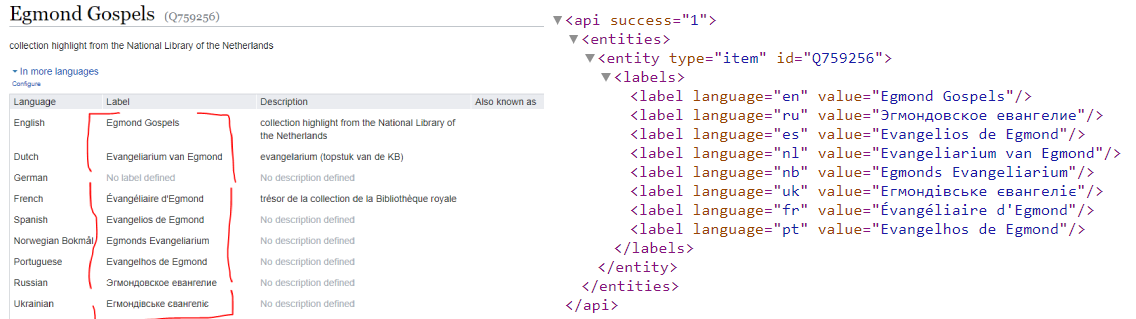
Comparison between the multilingual labeling of the Egmond Gospels (Q759256) from the Wikidata web interface and from the Wikidata API. Screenshot Wikidata GUI & Wikidata API, d.d. 30-04-2021 -
Get the aliases of Atlas Ortelius 1571 (Q67465742) in German, Czech, Polish and Ukrainian, as JSON: https://www.wikidata.org/w/api.php?action=wbgetentities&ids=Q67465742&props=aliases&languages=de%7Ccs%7Cpl%7Cuk&format=json
-
Get the Wikipedia articles for both Liber Pantegni (Q748421) and the Beyeren armorial (Q3372028) in all available languages, as XML: https://www.wikidata.org/w/api.php?action=wbgetentities&ids=Q748421%7CQ3372028&props=sitelinks&format=xml
44) Request full Wikidata items directly from the Qnumber (in HTML, JSON, JSON-LD, RDF, NT, TTL or N3 and PHP)
An alternative way is to request full Wikidata items directly from the Qnumber via a Special:EntityData URL. The ouput can be obtained in no fewer than seven different formats:
- Get all information from the Haags liederenhandschrift (Q16641064, The Hague song manuscript) as HTML: https://www.wikidata.org/wiki/Special:EntityData/Q16641064. This uses content negotiation to return HTML in your browser.
- If you don’t want to depend on content negotiation (e.g. view non-HTML content in a web browser), you can actively request alternative formats by appendig a format suffix to the URL, eg. to retrieve JSON: https://www.wikidata.org/wiki/Special:EntityData/Q16641064.json.
- Other available formats are JSON-LD, RDF, NT, TTL or N3 and PHP.
-
Equivalant URLs for these requests use the format argument, e.g. : Special:EntityData?id=Q16641064&format=rdf.
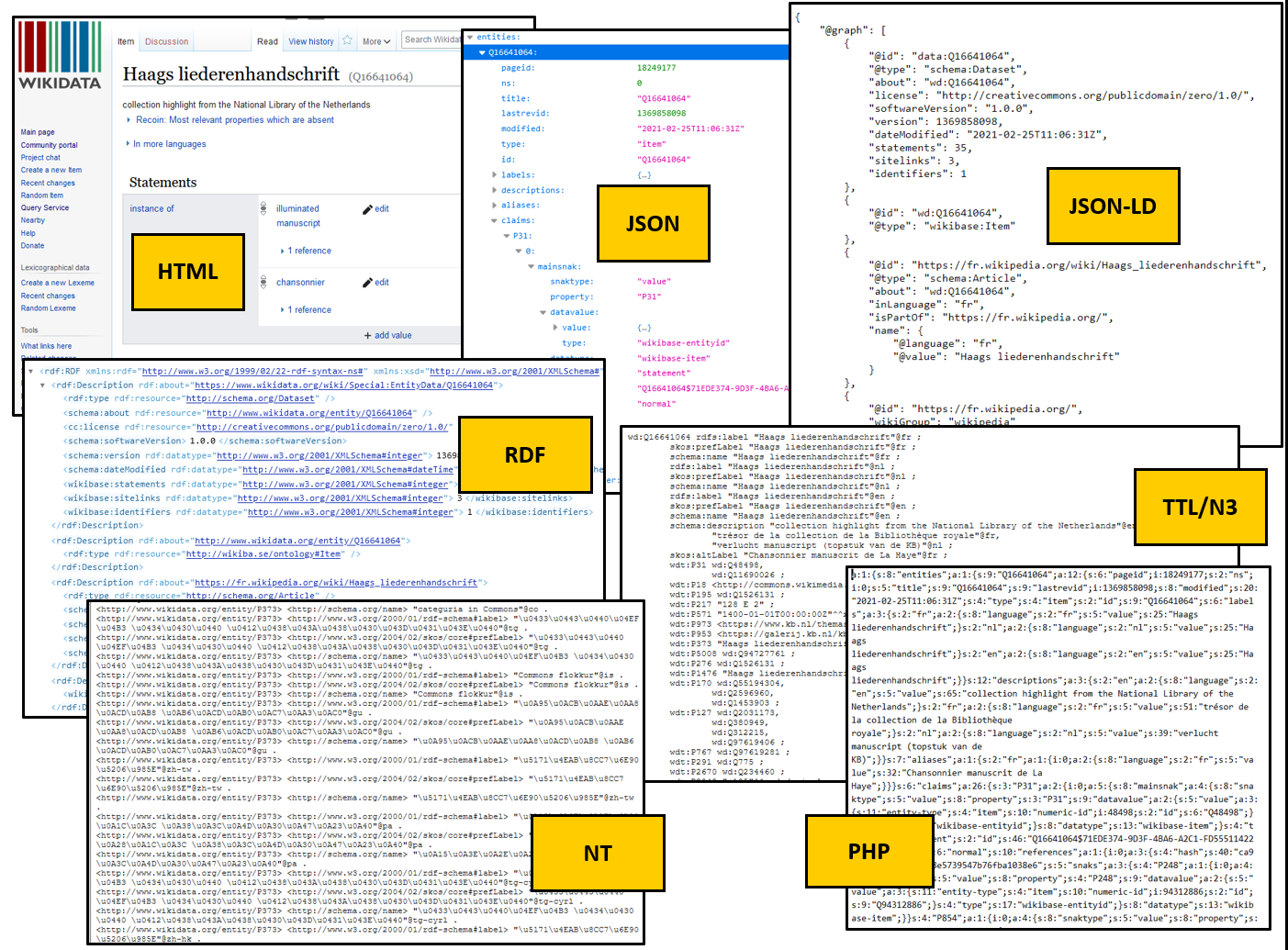
Seven different output formats for the Special:EntityData URL for the Haags liederenhandschrift (Q16641064): HTML, JSON, JSON-LD, RDF, NT, TTL or N3 and PHP. Compilation of screenshot d.d. 03-05-2021
For exploring the JSON response in further detail we can tweak this Python script that Matt Miller from the Library of Congress explains in Demo: Programmatic Wikidata from his YouTube series Programming for Cultural Heritage.
For instance, we can make a list of all Wikidata properties that are used in Q16641064
import requests
import json
url = "https://www.wikidata.org/wiki/Special:EntityData/"
qnumbers = ['Q16641064'] # Haags liederenhandschrift // The Hague song manuscript
for qnum in qnumbers:
useurl = url + qnum + '.json'
headers = {
'Accept' : 'application/json',
'User-Agent': 'User OlafJanssen - Haags liederenhandschrift'
}
r = requests.get(useurl, headers=headers)
data = json.loads(r.text)
properties = list(data['entities'][qnum]['claims'].keys())
print(properties)
returning a list in Python
['P31', 'P18', 'P195', 'P217', 'P571', 'P973', 'P953', 'P373', 'P5008', 'P276', 'P1476', 'P170', 'P127', 'P767',
'P291', 'P2670', 'P2048', 'P2049', 'P186', 'P1104', 'P935', 'P8791', 'P1343', 'P528', 'P6216', 'P2671']
If we modify the last couple of code lines into
.... # as previous
data = json.loads(r.text)
nlen= len(data['entities'][qnum]['claims']['P170'])
for i in range(0, nlen):
creatorid = data['entities'][qnum]['claims']['P170'][i]['mainsnak']['datavalue']['value']['id']
creatorurl= "https://www.wikidata.org/w/api.php?action=wbgetentities&ids=" + str(creatorid) +
"&props=labels&languages=en&format=json"
creatorresponse = requests.get(creatorurl, headers=headers)
creatordata = json.loads(creatorresponse.text)
print(str(i+1)+": "+creatordata['entities'][creatorid]['labels']['en']['value'])
we can retrieve the English names (labels) of the three creators (P170) of this manuscript:
1: Noydekijn
2: Augustijnken
3: Freidank
45) Get a structured, machine readable overview of persons and institutions related to KB highlights
Talking about creators, let’s see how we can request a structured overview of persons and institutions related to a set of highlights, such as authors, makers, contributors, publishers, printers, illustrators, translators, owners, collectors etc. This is actually the machine readable equivalent of points 9 and 10 from Part 2.
Let’s do this for three KB highlights at the same time: 1) Admirandorum quadruplex spectaculum (Q42302438), 2) Kunst en samenleving (Art and society, Q72752446) and the above mentioned 3) Haags liederenhandschrift (Q16641064).
We use this SPARQL query in Wikidata:
# Overview of persons & institutions related to
# 1 Admirandorum quadruplex spectaculum (Q42302438),
# 2 Kunst en samenleving (Q72752446) and
# 3 Haags liederenhandschrift (Q16641064)
# such as authors, makers, contributors, publishers, printers, illustrators, translators, owners etc.
SELECT DISTINCT ?hl ?hlLabel
(GROUP_CONCAT(DISTINCT ?creatorLabel ; separator = " ---- ") as ?creators)
(GROUP_CONCAT(DISTINCT ?authorLabel ; separator = " ---- ") as ?authors)
(GROUP_CONCAT(DISTINCT ?contributorLabel ; separator = " ---- ") as ?contributors)
(GROUP_CONCAT(DISTINCT ?editorLabel ; separator = " ---- ") as ?editors)
(GROUP_CONCAT(DISTINCT ?translatorLabel ; separator = " ---- ") as ?translators)
(GROUP_CONCAT(DISTINCT ?illustratorLabel ; separator = " ---- ") as ?illustrators)
(GROUP_CONCAT(DISTINCT ?publisherLabel ; separator = " ---- ") as ?publishers)
(GROUP_CONCAT(DISTINCT ?owned_byLabel ; separator = " ---- ") as ?owned_bys)
WHERE {
# the thing is part of the KB collection, and has role 'collection highlight' within that collection
?hl (p:P195/ps:P195) wd:Q1526131; p:P195 [pq:P2868 wd:Q29188408].
# limit to Q42302438, Q72752446 and Q16641064
VALUES ?hl {wd:Q42302438 wd:Q72752446 wd:Q16641064}
OPTIONAL{?hl wdt:P170 ?creator.}
OPTIONAL{?hl wdt:P50 ?author.}
OPTIONAL{?hl wdt:P767 ?contributor.}
OPTIONAL{?hl wdt:P98 ?editor.}
OPTIONAL{?hl wdt:P655 ?translator.}
OPTIONAL{?hl wdt:P110 ?illustrator.}
OPTIONAL{?hl wdt:P123 ?publisher.}
OPTIONAL{?hl wdt:P127 ?owned_by.}
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". ?hl rdfs:label ?hlLabel.
?creator rdfs:label ?creatorLabel. ?author rdfs:label ?authorLabel.
?contributor rdfs:label ?contributorLabel. ?editor rdfs:label ?editorLabel.
?translator rdfs:label ?translatorLabel. ?illustrator rdfs:label ?illustratorLabel.
?publisher rdfs:label ?publisherLabel. ?owned_by rdfs:label ?owned_byLabel.}
}
GROUP BY ?hl ?hlLabel
ORDER BY ?hlLabel
resulting into

Persons and institutions related to Q42302438, Q72752446 and Q16641064. Screenshot Wikidata query service, d.d. 11-05-2021
In this query the properties that return no results for any of the these highlights have been omitted (eg. none of the three highlights has values for P872 - Printer, so P872 was not included in the query)
Of course you can also request the JSON reponse or use a Pyhton script to make the request to the Wikidata SPARQL query service:
# pip install sparqlwrapper
# https://rdflib.github.io/sparqlwrapper/
import sys, json
from SPARQLWrapper import SPARQLWrapper, JSON
endpoint_url = "https://query.wikidata.org/sparql"
query = """
SELECT DISTINCT ?hl ?hlLabel
(GROUP_CONCAT(DISTINCT ?creatorLabel ; separator = " ---- ") as ?creators)
(GROUP_CONCAT(DISTINCT ?authorLabel ; separator = " ---- ") as ?authors)
(GROUP_CONCAT(DISTINCT ?contributorLabel ; separator = " ---- ") as ?contributors)
(GROUP_CONCAT(DISTINCT ?editorLabel ; separator = " ---- ") as ?editors)
(GROUP_CONCAT(DISTINCT ?translatorLabel ; separator = " ---- ") as ?translators)
(GROUP_CONCAT(DISTINCT ?illustratorLabel ; separator = " ---- ") as ?illustrators)
(GROUP_CONCAT(DISTINCT ?publisherLabel ; separator = " ---- ") as ?publishers)
(GROUP_CONCAT(DISTINCT ?owned_byLabel ; separator = " ---- ") as ?owned_bys)
WHERE {
?hl (p:P195/ps:P195) wd:Q1526131; p:P195 [pq:P2868 wd:Q29188408].
VALUES ?hl {wd:Q42302438 wd:Q72752446 wd:Q16641064}
OPTIONAL{?hl wdt:P170 ?creator.}
OPTIONAL{?hl wdt:P50 ?author.}
OPTIONAL{?hl wdt:P767 ?contributor.}
OPTIONAL{?hl wdt:P98 ?editor.}
OPTIONAL{?hl wdt:P655 ?translator.}
OPTIONAL{?hl wdt:P110 ?illustrator.}
OPTIONAL{?hl wdt:P123 ?publisher.}
OPTIONAL{?hl wdt:P127 ?owned_by.}
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". ?hl rdfs:label ?hlLabel.
?creator rdfs:label ?creatorLabel. ?author rdfs:label ?authorLabel.
?contributor rdfs:label ?contributorLabel. ?editor rdfs:label ?editorLabel.
?translator rdfs:label ?translatorLabel. ?illustrator rdfs:label ?illustratorLabel.
?publisher rdfs:label ?publisherLabel. ?owned_by rdfs:label ?owned_byLabel.}
}
GROUP BY ?hl ?hlLabel
ORDER BY ?hlLabel
"""
def get_results(endpoint_url, query):
user_agent = "WDQS-example Python/%s.%s" % (sys.version_info[0], sys.version_info[1])
# User-Agent policy, see https://w.wiki/CX6
sparql = SPARQLWrapper(endpoint_url, agent=user_agent)
sparql.setQuery(query)
sparql.setReturnFormat(JSON)
return sparql.query().convert()
results = get_results(endpoint_url, query)
for result in results["results"]["bindings"]:
print(result)
giving an output of three Python dictionaries:
{'hl': {'type': 'uri', 'value': 'http://www.wikidata.org/entity/Q42302438'}, 'hlLabel': {'xml:lang': 'en', 'type': 'literal', 'value': 'Admirandorum quadruplex spectaculum'}, 'creators': {'type': 'literal', 'value': 'Jan van Call'}, 'authors': {'type': 'literal', 'value': ''}, 'contributors': {'type': 'literal', 'value': ''}, 'editors': {'type': 'literal', 'value': ''}, 'translators': {'type': 'literal', 'value': ''}, 'illustrators': {'type': 'literal', 'value': 'Jan van Call'}, 'publishers': {'type': 'literal', 'value': 'Peter Schenk the Elder'}, 'owned_bys': {'type': 'literal', 'value': 'Aleida Betsy Terpstra'}}
{'hl': {'type': 'uri', 'value': 'http://www.wikidata.org/entity/Q16641064'}, 'hlLabel': {'xml:lang': 'en', 'type': 'literal', 'value': 'Haags liederenhandschrift'}, 'creators': {'type': 'literal', 'value': 'Freidank ---- Augustijnken ---- Noydekijn'}, 'authors': {'type': 'literal', 'value': ''}, 'contributors': {'type': 'literal', 'value': 'Eerste stadhouderlijke binderij'}, 'editors': {'type': 'literal', 'value': ''}, 'translators': {'type': 'literal', 'value': ''}, 'illustrators': {'type': 'literal', 'value': ''}, 'publishers': {'type': 'literal', 'value': ''}, 'owned_bys': {'type': 'literal', 'value': 'William V ---- William IV, Prince of Orange ---- Matilda of Guelders ---- Stadhouderlijke bibliotheek'}}
{'hl': {'type': 'uri', 'value': 'http://www.wikidata.org/entity/Q72752446'}, 'hlLabel': {'xml:lang': 'en', 'type': 'literal', 'value': 'Kunst en samenleving'}, 'creators': {'type': 'literal', 'value': ''}, 'authors': {'type': 'literal', 'value': 'Walter Crane'}, 'contributors': {'type': 'literal', 'value': 'Gerrit Willem Dijsselhof'}, 'editors': {'type': 'literal', 'value': 'Jan Veth'}, 'translators': {'type': 'literal', 'value': 'Jan Veth'}, 'illustrators': {'type': 'literal', 'value': ''}, 'publishers': {'type': 'literal', 'value': 'Scheltema en Holkema'}, 'owned_bys': {'type': 'literal', 'value': ''}}
46) Generating off-Wiki image galleries
In points 22-25 of Part 3 we looked at the portraits, genders, occupations and lifespans of the people who contributed to the Album amicorum Jacob Heyblocq and created an on-Wiki portrait gallery/facebook of album contributors directly from a Wikidata SPARQL query.
Let’s now look at three approaches for generating off-Wiki image galleries from the Wikimedia infrastructure. The following examples are detailed in (and extracted from) the article Reusing the album amicorum Jacob Heyblocq - Image gallery of album contributors here on Github.
1) An HTML facebook based on the Wikimedia Commons API - From the JSON response of the Wikimedia Commons query API and using this Python script we can generate a basic HTML portrait gallery of contributors.
2) An HTML facebook based on the Wikidata SPARQL service with a JSON response - From the JSON response of the Wikidata query service and using this Python script we can create this basic HTML portrait gallery.
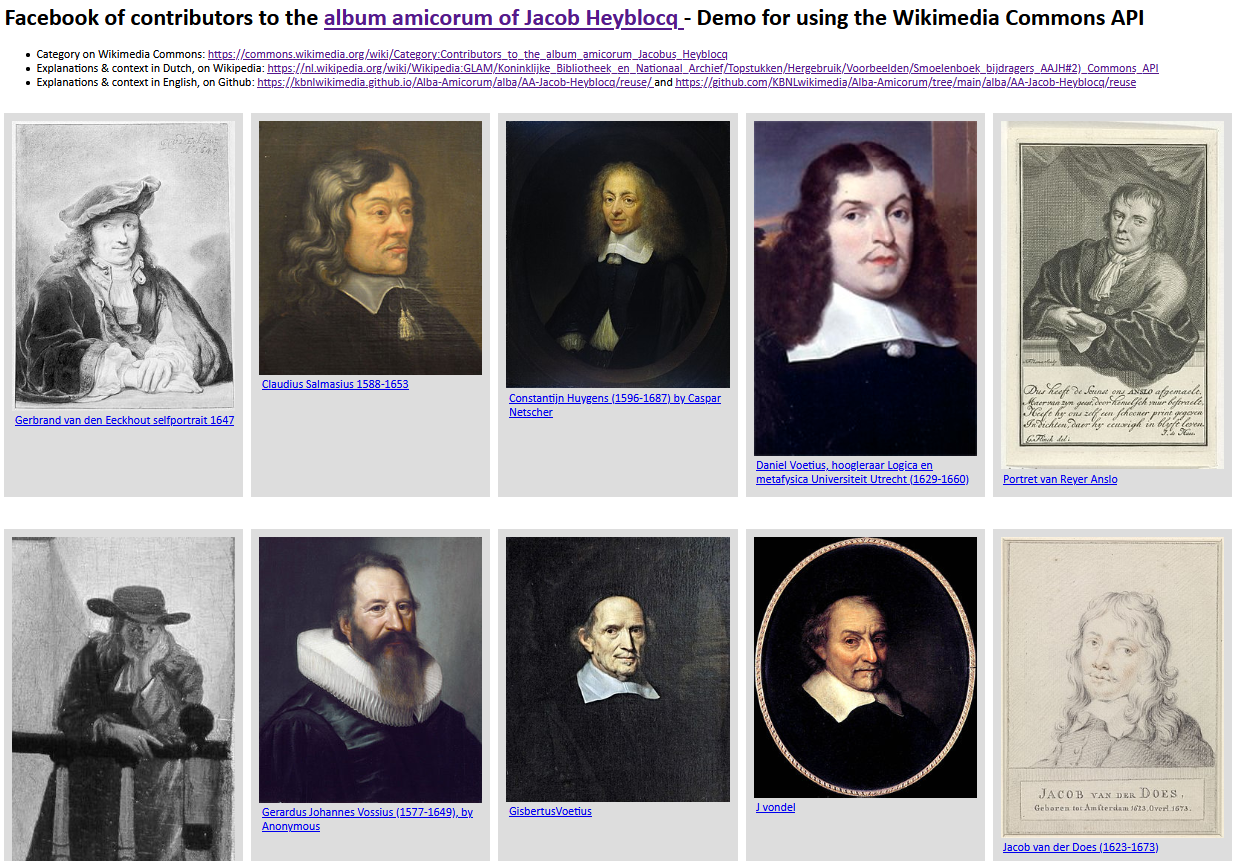
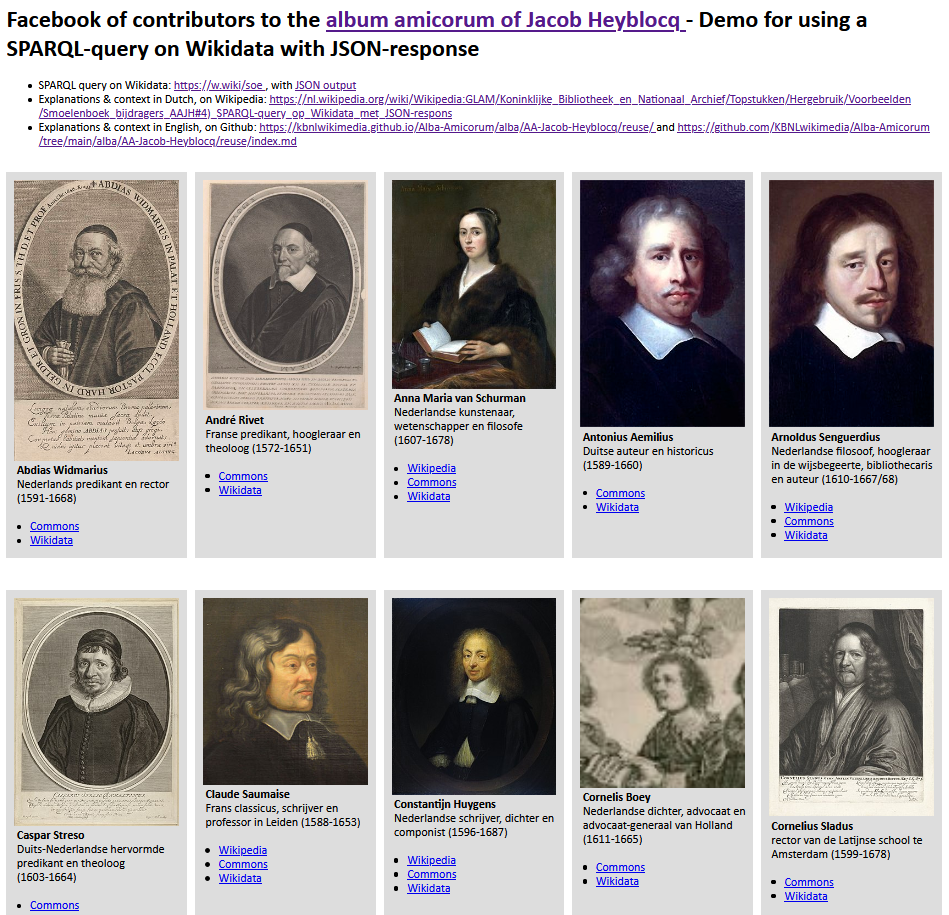
Two approaches for making a HTML portrait gallery of contributors to the Album amicorum Jacob Heyblocq. Left: using the Wikimedia Commons API. Right: using the Wikidata SPARQL service with a JSON response. Screenshots d.d. 14-05-2021
3) An HTML facebook from a Wikidata SPARQL query using an embedded iframe - Using the same query as above, we can also embed the result into an HTML page by means of an iframe:
<!DOCTYPE html>
<html>
<head>
<title>Facebook of contributors to the album amicorum Jacobus Heyblocq - Wikidata SPARQL + HTML iframe</title>
</head>
<body>
<h1>Facebook of contributors to the album amicorum Jacobus Heyblocq - Wikidata SPARQL + HTML iframe</h1>
<iframe style="position: absolute; height: 100%; width: 100%; border: none" src="https://w.wiki/phx" referrerpolicy="origin" sandbox="allow-scripts allow-same-origin allow-popups"></iframe>
</body>
</html>
This results into a plain, unstyled facebook.
We can expand this approach into a design that fits seamlessly into the pages about the album on the KB website, resulting into a KB styled facebook.
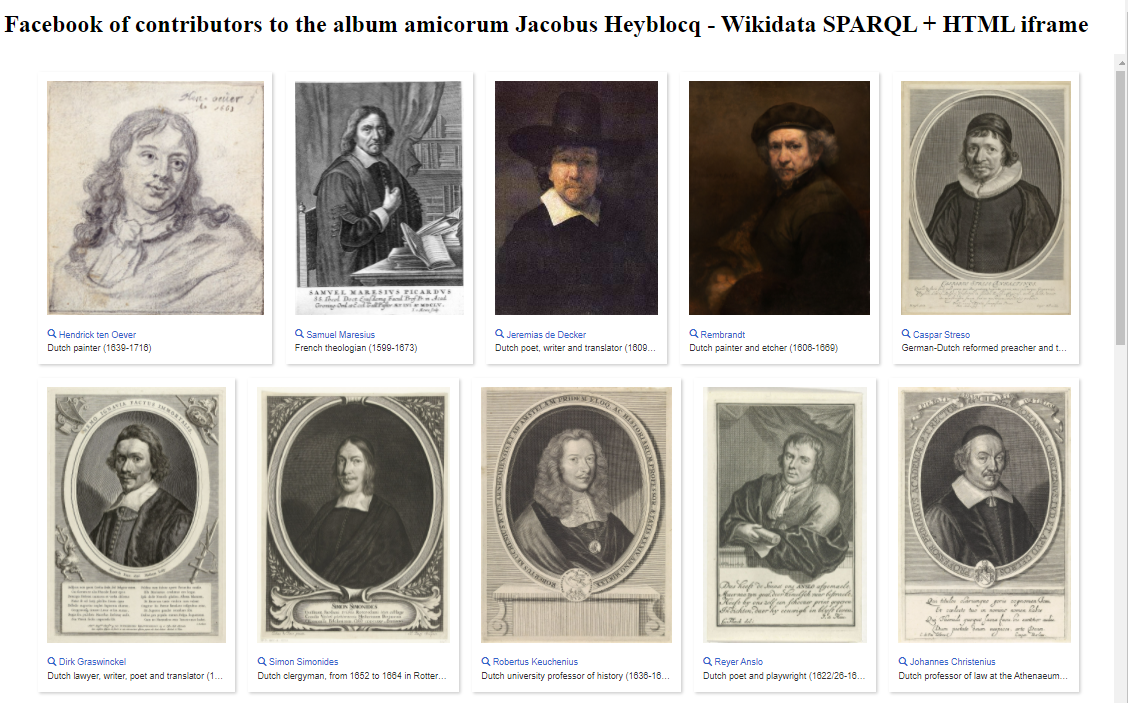
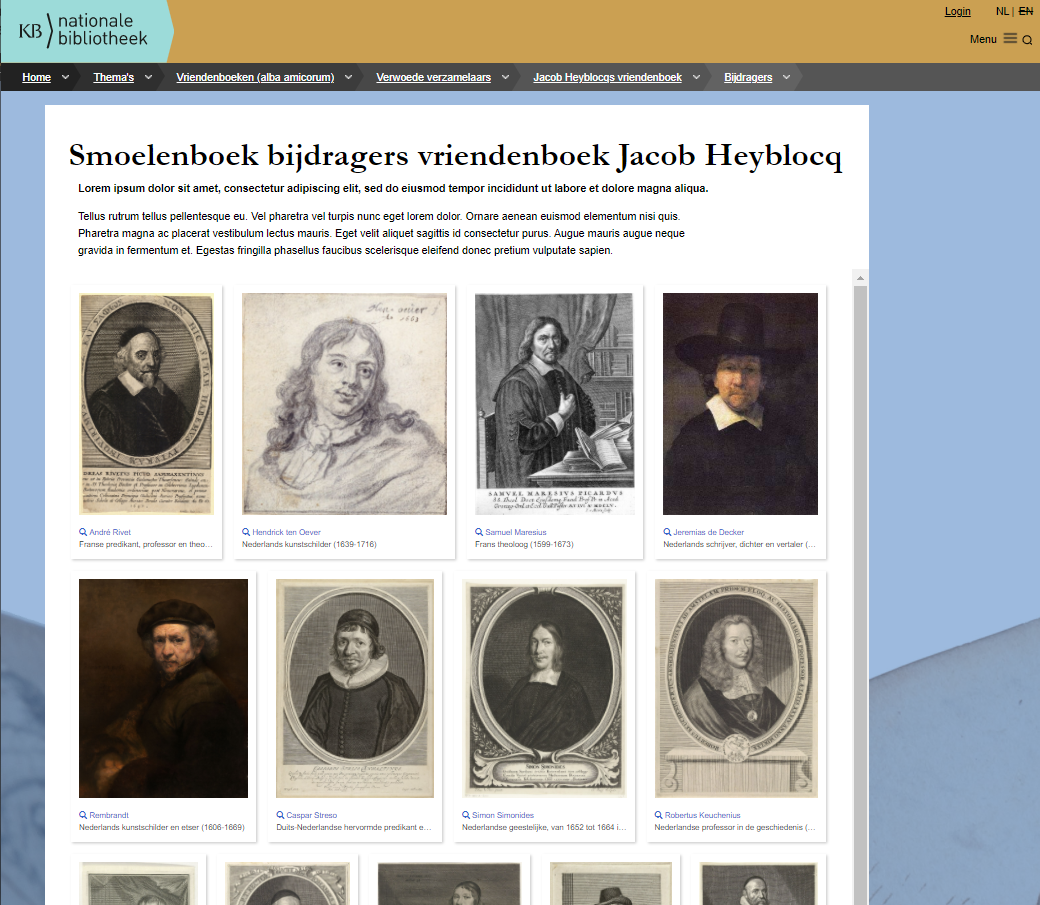
Another approach for making a HTML portrait gallery of contributors to the Album amicorum Jacob Heyblocq, using a Wikidata SPARQL query and an embedded iframe. Left: A plain, unstyled facebook. Right: The same iframe, but now embedded into a KB styled portrait gallery. Screenshots d.d. 14-05-2021
47) Programmatically retrieve things depicted in images
In items 33 and 35 of Part 4 we already looked at things (Wikidata entities) that can be seen in KB collection highlights, making images not only discoverable via the regular metadata, but also multilingually searchable by content (What’s depicted in it?). Let’s now look at how we can retrieve depicted entities programmatically. We’ll use Atlas de Wit 1698 for this . We can do this either via a) the Wikimedia Commons SPARQL query service, b) the Wikimedia Commons API or c) via the Petscan tool.
a) To retrieve the depicted entities via the Wikimedia Commons SPARQL query service, we use this query:
#Things depicted in Atlas de Wit 1698
SELECT ?file (GROUP_CONCAT(DISTINCT ?depictionLabel ; separator = " -- ") as ?ThingsDepicted)
WHERE {
?file wdt:P6243 wd:Q2520345 .
?file wdt:P180 ?depiction .
SERVICE <https://query.wikidata.org/sparql> {
SERVICE wikibase:label {
bd:serviceParam wikibase:language "en" .
?depiction rdfs:label ?depictionLabel.
?file rdfs:label ?fileLabel.
}
}
}
GROUP BY ?file
giving this result, which can also be requested as JSON.
Things depicted in Atlas de Wit 1698. Screenshot Wikimedia Commons SPARQL query service d.d. 15-05-2021
b) The Wikimedia Commons API allows us to retrieve depicted entities for individual images. Let’s use https://commons.wikimedia.org/wiki/File:Atlas_de_Wit_1698-pl048-Montfoort-KB_PPN_145205088.jpg as an example. As can be seen from the Concept URI link in the Tools navigation on the left, this file can also be requested via the URI https://commons.wikimedia.org/entity/M32093127, where ‘32093127’ is the Page ID that is listed in the Page information, also in the left hand navigation. This Mnumber is Wikimedia Commons’ equivalent of the Wikidata Qnumber.
{kind=link}
{kind=link}
From that Mnumber (M+Page ID) we can request the (Wikidata Qnumbers of the) depicted entities via the API call https://commons.wikimedia.org/w/api.php?action=wbgetentities&format=json&ids=M32093127 as JSON:

Wikidata Qnumbers of things depicted in File:Atlas de Wit 1698-pl048-Montfoort-KB PPN 145205088.jpg (M32093127). Result of this API call. Screenshot Wikimedia Commons API, d.d. 15-05-2021
If we want to make an English list of all things depicted in all images in Category:Atlas de Wit 1698, we can write a small Python script to iterate over all images in that category, using the API call we saw in item 41 to request the pageIDs and titles of the files in that category:
import requests
import json
baseurl = "https://commons.wikimedia.org/w/api.php?action="
cat = "Category:Atlas_de_Wit_1698"
headers = {'Accept' : 'application/json', 'User-Agent': 'User OlafJanssen - Category:Atlas_de_Wit_1698'}
filesurl= baseurl + "query&generator=categorymembers&gcmlimit=500&gcmtitle=" + cat + "&format=json&gcmnamespace=6"
files = requests.get(filesurl, headers=headers)
filesdata = json.loads(files.text)
pageids=list(filesdata['query']['pages'].keys())
taglang = 'en' #Language of P180 tags
for pageid in pageids:
mnumber="M"+str(pageid)
pageurl= baseurl + "wbgetentities&format=json&ids=" + str(mnumber)
pageresponse = requests.get(pageurl, headers=headers)
pagedata = json.loads(pageresponse.text)
pagetitle=pagedata.get('entities').get(mnumber).get('title')
p180s = pagedata.get('entities').get(mnumber).get('statements').get('P180', 'XX')
if str(p180s) != "XX":
depictslist=[]
for p in range(0, len(p180s)):
qnum= p180s[p]['mainsnak']['datavalue']['value']['id']
depictsurl = "https://www.wikidata.org/w/api.php?action=wbgetentities&ids=" + str(qnum) + "&props=labels&languages="+str(taglang)+"&format=json"
depictsresponse = requests.get(depictsurl, headers=headers)
depictsdata = json.loads(depictsresponse.text)
depicts = depictsdata.get('entities', 'XX').get(qnum).get('labels', 'XX').get(taglang, 'XX')
if str(depicts) != "XX":
a = str(depicts.get('value')) + " (https://www.wikidata.org/wiki/" + str(qnum) + ")"
depictslist.append(a)
print(str(mnumber) + " || " + str(pagetitle) + " || " + ' -- '.join(depictslist))
The taglang = ‘en’ asks for the English language labels. This script gives the following result:
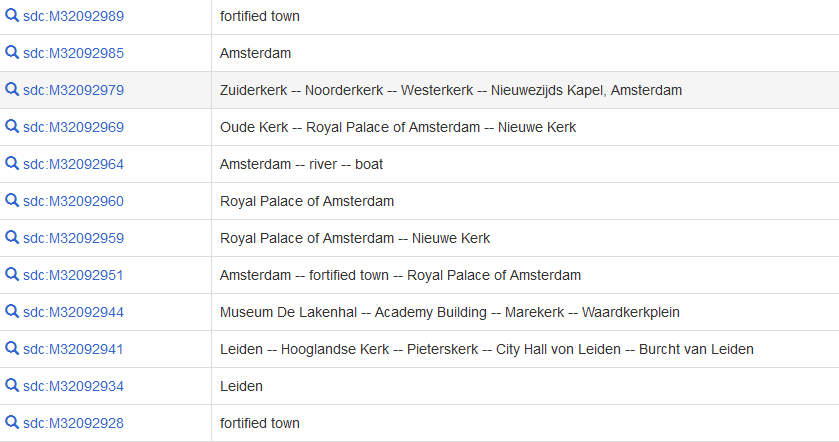
M32246841 || File:Atlas de Wit 1698-pl017-Leiden-de burcht.jpg || tree (Q10884) -- peafowl (Q201251) -- dog (Q144) -- Burcht van Leiden (Q2345558) -- gate (Q53060)
M32092934 || File:Atlas de Wit 1698-pl017-Leiden-KB PPN 145205088.jpg || Leiden (Q43631) -- Rhine (Q584) -- Oude Rijn (Q2478570) -- Nieuwe Rijn (Q671841) -- Nieuwe Rijn (Q57945772) -- Pieterskerk (Q1537972) -- Hooglandse Kerk (Q1537970) -- Rapenburg (Q2597656) -- Academy Building (Q2515805) -- Hortus Botanicus Leiden (Q2468128) -- Zijlpoort (Q2326072) -- bolwerk (Q891475) -- fortified town (Q677678) -- Morschpoort, Leiden (Q2688448) -- Marepoort (Q1817627) -- Burcht van Leiden (Q2345558)
M32246845 || File:Atlas de Wit 1698-pl017-Leiden-Pieterskerk.jpg || Pieterskerk (Q1537972) -- tree (Q10884) -- dog (Q144) -- weather vane (Q524738)
M32246848 || File:Atlas de Wit 1698-pl017-Leiden-St Pancraskerk.jpg || Hooglandse Kerk (Q1537970) -- cloud (Q8074) -- weathercock (Q2157687) -- leadlight (Q488094) -- door (Q36794) -- woman (Q467) -- child (Q7569) -- dog (Q144) -- hat (Q80151) -- carriage (Q235356) -- walking stick (Q1347864) -- horse (Q726) -- tree (Q10884) -- crow-stepped gable (Q1939660) -- clock (Q376) -- Burcht van Leiden (Q2345558)
M32246852 || File:Atlas de Wit 1698-pl017-Leiden-stadhuis.jpg || Leiden City Hall (Q2191676) -- dog (Q144) -- crow-stepped gable (Q1939660) -- cow (Q11748378)
M32092941 || File:Atlas de Wit 1698-pl017a-Leiden, Stadhuis-KB PPN 145205088.jpg || Leiden City Hall (Q2191676) -- Hooglandse Kerk (Q1537970) -- Leiden (Q43631) -- Burcht van Leiden (Q2345558) -- dog (Q144) -- cow (Q11748378) -- peafowl (Q201251) -- Pieterskerk (Q1537972) -- coach (Q4655519) -- crow-stepped gable (Q1939660) -- gate (Q53060)
....
M32092951 || File:Atlas de Wit 1698-pl018-Amsterdam-KB PPN 145205088.jpg || Amsterdam (Q727) -- Royal Palace of Amsterdam (Q1056152) -- fortified town (Q677678)
M32092959 || File:Atlas de Wit 1698-pl018a-Amsterdam, Dam-KB PPN 145205088.jpg || Dam Square (Q839050) -- Royal Palace of Amsterdam (Q1056152) -- dog (Q144) -- horse (Q726) -- fire extinguisher (Q190672) -- fire department (Q6498663) -- Nieuwe Kerk (Q1419675) -- weigh house (Q1407236) -- Oude Kerk (Q623558) -- pump (Q134574) -- fire hose (Q1410061) -- firewater (Q5452025) -- coat of arms of Amsterdam (Q683829)
M32092960 || File:Atlas de Wit 1698-pl018b-Amsterdam, Stadhuis-KB PPN 145205088.jpg || Royal Palace of Amsterdam (Q1056152)
M32092964 || File:Atlas de Wit 1698-pl018c-Amsterdam, profiel (Joan de Ram)-KB PPN 145205088.jpg || Amsterdam (Q727) -- boat (Q35872) -- river (Q4022)
M32092969 || File:Atlas de Wit 1698-pl018d-Amsterdam, Oude Kerk-KB PPN 145205088.jpg || Royal Palace of Amsterdam (Q1056152) -- weigh house (Q1407236) -- Nieuwe Kerk (Q1419675) -- market (Q37654) -- horse (Q726) -- Euronext Amsterdam (Q478720) -- exchange building (Q10882966) -- Oude Kerk (Q623558) -- péniche (Q7578326) -- porter (Q1509714) -- coat of arms of Amsterdam (Q683829) -- dog (Q144)
.....
c) An alternative way of finding the pageIDs of the category members is by using the JSON response of the PetScan tool for the given category. I leave it to the reader to implement this approach into the Python script.
48) Extract information from external databases starting from Wikidata identifiers
In item 46 we looked at portrait galleries of the contributors to the Album amicorum Jacob Heyblocq, where the portraits were stored in the Wikimedia infrastructure (Wikimedia Commons to be exact). Let’s now look at external (non-Wikimedia) databases describing these persons, their images, works and their lives. For instance let’s look at
- Europeana - access to millions of European books, music, artworks etc.
- RKD - the Netherlands Institute for Art History.
- Biografisch Portaal - scientific information about prominent figures from Dutch history.
- DBNL - the Digital Library of Dutch Literature, a collection of primary and secondary information on Dutch language and literature.
Each database has its associated Wikidata property:
- Europeana entity - P7704
- RKDartists ID - P650
- Biografisch Portaal van Nederland ID - P651
- Digitale Bibliotheek voor de Nederlandse Letteren author ID - P723
Let’s start by querying Wikidata to see which AAJH contributors have any of these properties connected to them:
SELECT DISTINCT ?contr ?contrLabel ?EuropeanaID ?EuropeanaURI ?RKDID ?RKDURI ?BPID ?BPURI ?DBNLaID ?DBNLaURI
WHERE {
wd:Q72752496 wdt:P767 ?contr.
OPTIONAL { ?contr wdt:P7704 ?EuropeanaID.
BIND(URI(CONCAT(concat("https://www.europeana.eu/api/entities/",?EuropeanaID ,".json?wskey=apidemo")) as ?EuropeanaURI)}
OPTIONAL {?contr wdt:P650 ?RKDID.
BIND(URI(CONCAT("https://api.rkd.nl/api/record/artists/",?RKDID ,"?format=json")) as ?RKDURI)}
OPTIONAL {?contr wdt:P651 ?BPID.
BIND(URI(CONCAT("http://www.biografischportaal.nl/persoon/json/", ?BPID)) as ?BPURI)} # http://www.biografischportaal.nl/about/bioport-api-documentation
OPTIONAL {?contr wdt:P723 ?DBNLaID.
BIND(URI(CONCAT("http://data.bibliotheken.nl/doc/dbnla/",?DBNLaID ,".json")) as ?DBNLaURI)}
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
ORDER BY DESC(?EuropeanaID)
Via the BIND(URI(CONCAT())) operators we constructed direct URIs for retrieving JSON responses from the databases. This query results into this JSON result, or this table:
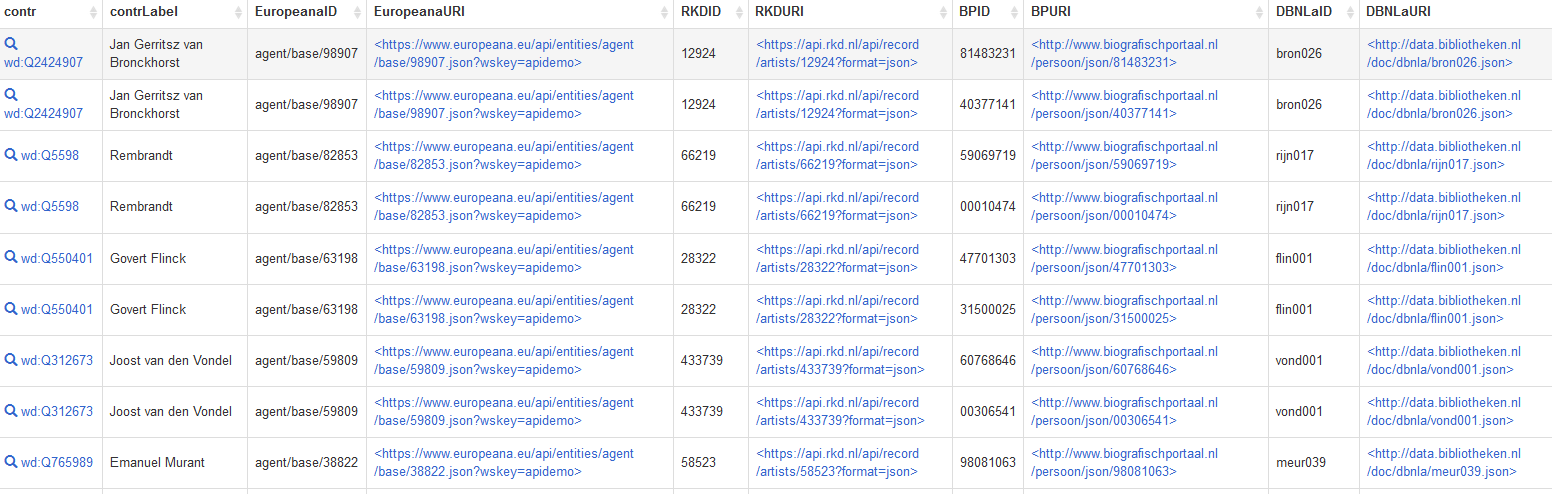
Europeana, RDK, BiografischePortaal and DBNL identifiers and JSON URIs for the contributors of the Album amicorum Jacob Heyblocq, as retrieved from Wikidata. Screenshot Wikidata query service, d.d. 16-05-2021
Once retrieved, we can now use these JSON URIs as starting points to further dive into the REST APIs of these databases and retrieve information from them that is not available in the Wikimedia infrastructure. Let’s elaborate this for the Europeana REST APIs (columns 3 and 4 in the above screenshot).
For instance, let’s look at Govert Flinck with Wikidata Q550401, Europeana agent/base/63198 and EuropeanaURI https://www.europeana.eu/api/entities/agent/base/63198.json?wskey=apidemo.
The works by Govert Flinck can be retrieved via http://data.europeana.eu/agent/base/63198, which redirects to the Europeana website https://www.europeana.eu/en/collections/person/63198-govert-flinck. This result set can also be requested as JSON via the API call https://www.europeana.eu/api/v2/search.json?wskey=api2demo&media=true&start=1&rows=100&profile=minimal&query=%22http://data.europeana.eu/agent/base/63198%22, retrieving results 1-100 (&start=1&rows=100&), as documented here.
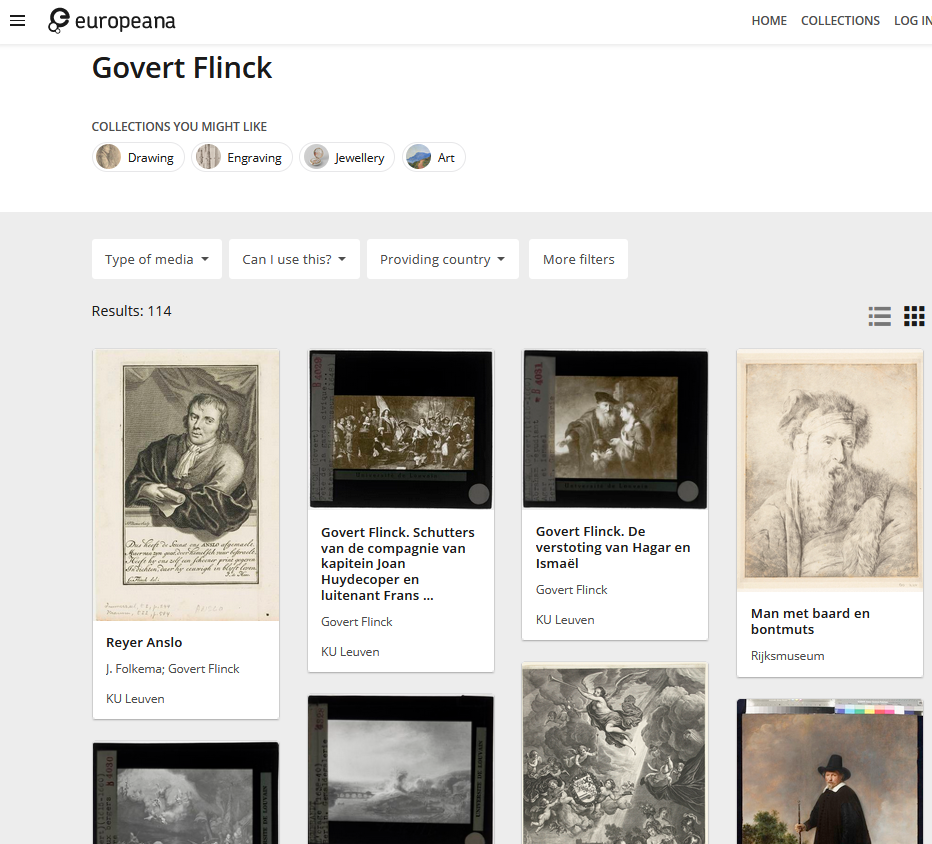

Works by Govert Flinck as listed on the Europena website (left) and in the Europeana API, first 100 results as JSON (right). Screenshots Europeana website and API, d.d. 01-06-2021
One of Flinck’s works on Europeana is Schutters van de compagnie van kapitein Joan Huydecoper en luitenant Frans van Waveren, which can be represented in JSON via https://api.europeana.eu/record/2024903/photography_ProvidedCHO_KU_Leuven_9990688460101488.json?wskey=api2demo.
This work is in the collection of the KU Leuven University, where the full image is available via https://lib.is/IE2392190/stream?quality=LOW. A thumbnail can be generated using the Europeana API: https://api.europeana.eu/thumbnail/v2/url.json?uri=https%3A%2F%2Flib.is%2FIE2392190%2Fstream%3Fquality%3DLOW&type=IMAGE
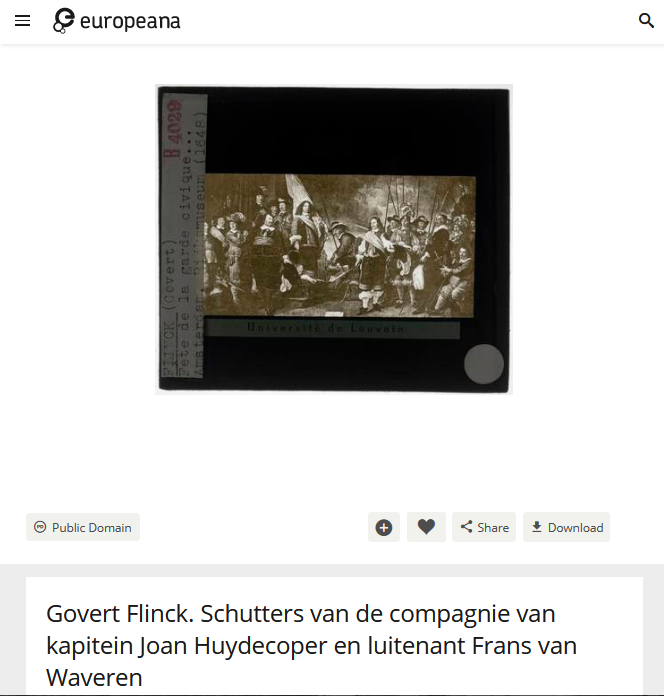
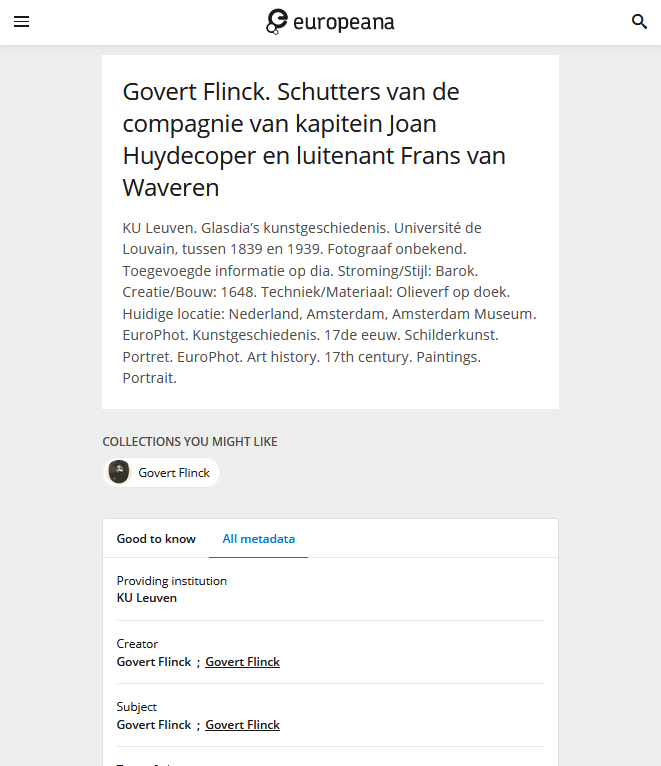
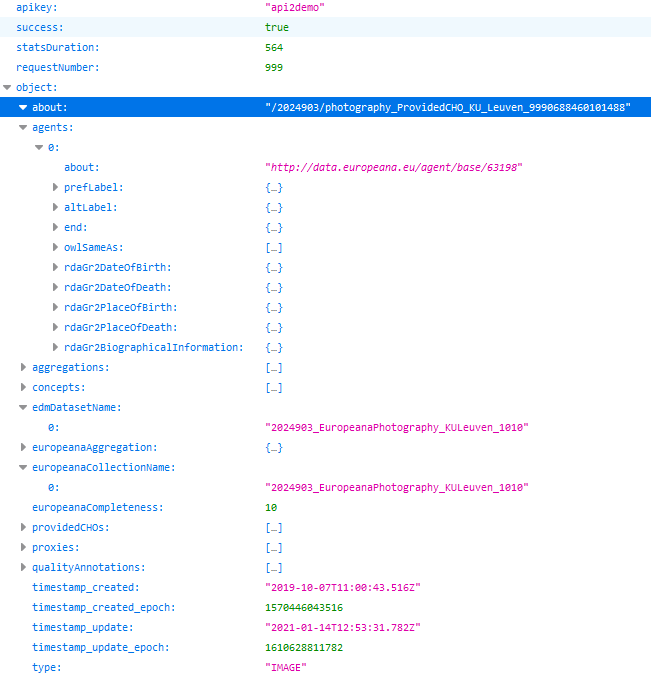
Image and metadata for Schutters van de compagnie van kapitein Joan Huydecoper en luitenant Frans van Waveren by Govert Flinck on the Europena website (left, middle) and as JSON from the Europeana API (right). Screenshots Europeana, d.d. 01-06-2021
So using its API, we can use Europeana to programmatically find various pieces of interesting information about a single artwork by a single contributor to the Album amicorum Jacob Heyblocq. We can extend this approach to include all artworks (as far as they are known in Europeana) by all album contributors (as far as they are known in Europeana). We did this by writing this Python script. Please note this script is work in progress, so it is not fully finished, complete and/or reliable, but it should give the reader an idea of an approach for programmatically retrieving data from Europeana. Using Pycharm IDE for running it, the console output looks like this:
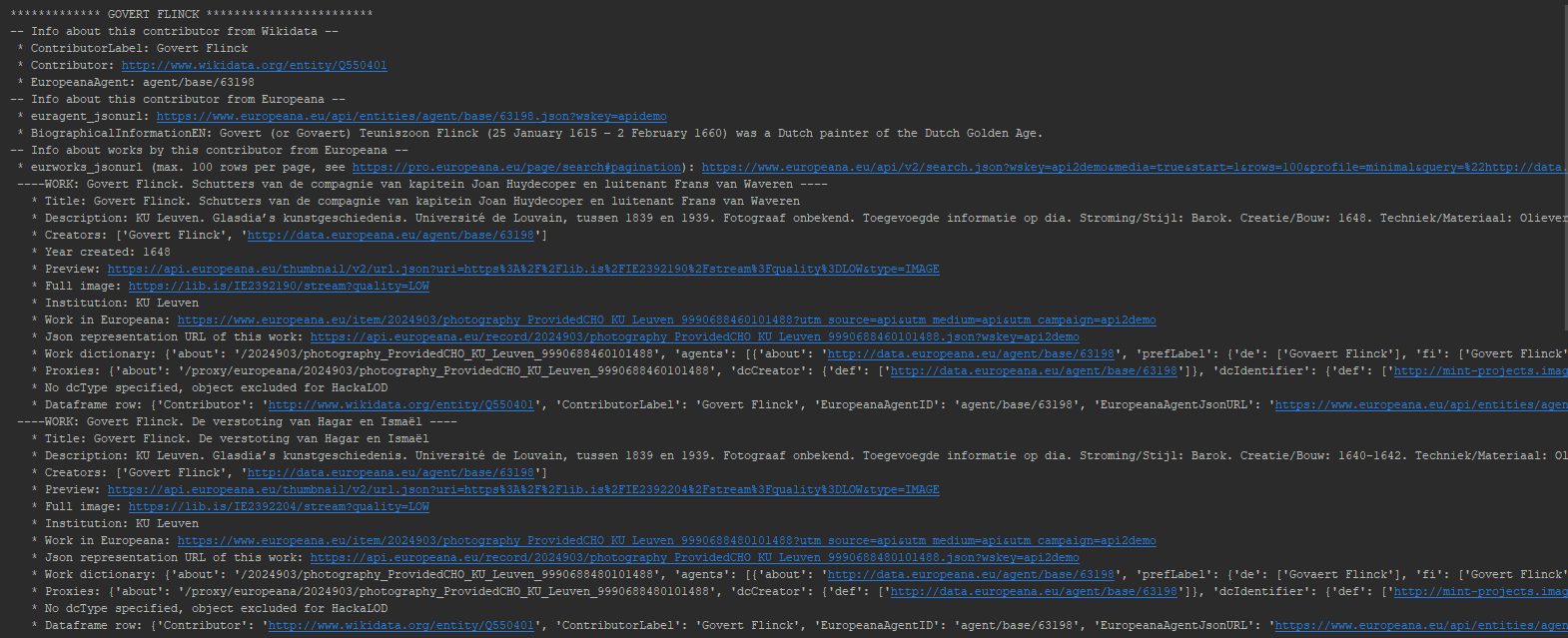
Console output of a Python script for finding works in Europeana by the contributors to the Album amicorum Jacob Heyblocq. The results for Govert Flinck are dislayed. Screenshot Pycharm IDE, d.d. 01-06-2021
The output is also written to this Excel file.
49) Extract information simultaneously from both Wikidata and external databases using federated SPARQL queries
We can combine a SPARQL query in Wikidata with simultaneous queries in other SPARQL endpoints. This is called federated SPARQL querying and we can use it to extract some base information from Wikidata and combine that with additional, enriching information from other, external (linked open) databases.
Let’s say we want to look for Dutch literary works written by the contributors of the Album amicorum Jacob Heyblocq, as stored in the DBNL website and retrieve (the URLs of) the first pages of those works. We can construct this federated SPARQL query for that:
# Look for Dutch literary works written by the contributors of the Album amicorum Jacob Heyblocq in www.dbnl.org
# and retrieve (the URLs of) the first pages of those works
PREFIX schema: <http://schema.org/>
SELECT DISTINCT ?WDcontr ?WDcontrLabel ?WDDBNLaID #Wikidata stuff
?DBNLauthorURL ?DBNLauthorName #DBNL author stuff, as is ?authorid
?DBNLworkID ?DBNLworkURL ?DBNLworkTitle #DBNL work stuff
?DBNLwebsiteURL ?DBNLtextURL #DBNL website stuff
WHERE {wd:Q72752496 wdt:P767 ?WDcontr.
?WDcontr wdt:P723 ?WDDBNLaID.
SERVICE <http://data.bibliotheken.nl/sparql>{
?DBNLauthorURL schema:identifier ?WDDBNLaID;
schema:name ?DBNLauthorName;
schema:mainEntityOfPage ?page.
?page schema:mainEntity ?authorid.
?DBNLworkURL schema:author ?authorid;
schema:identifier ?DBNLworkID;
schema:name ?DBNLworkTitle;
schema:url ?DBNLwebsiteURL.
}
BIND(URI(CONCAT("http://www.dbnl.org/tekst/", ?DBNLworkID, "_01/",?DBNLworkID,"_01_0001.php")) as ?DBNLtextURL)
SERVICE wikibase:label {bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en".}
}
LIMIT 150
After having retrieved the base information about a contributor (author) from Wikidata (?WDcontr, ?WDcontrLabel, ?WDDBNLaID), we use WDDBNLaID to find information about the author in http://data.bibliotheken.nl, the LOD triplestore of the KB (?DBNLauthorURL, ?DBNLauthorName, ?authorid). From there we find information about the works that the author wrote (?DBNLworkID, ?DBNLworkURL, ?DBNLworkTitle). In the last step we find two links to the DBNL website (?DBNLwebsiteURL, ?DBNLtextURL), where the latter is the link to the first page of the work.
This query results into a list or a JSON response (query might be slow).
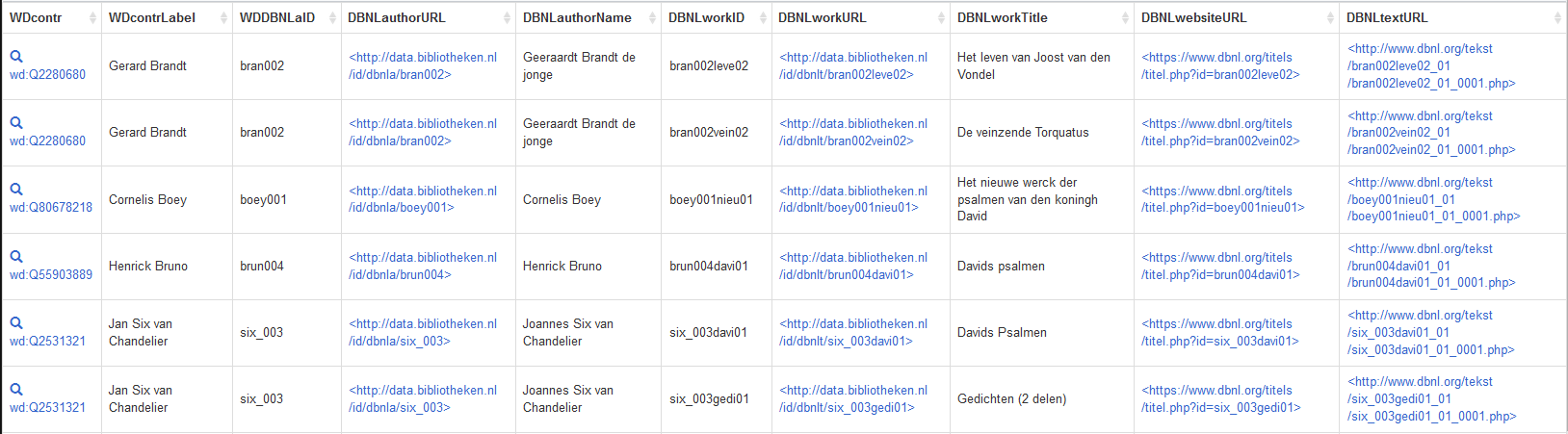
Dutch literary works in the DBNL website written by the contributors of the Album amicorum Jacob Heyblocq, obtained by a federated SPARQL query in both Wikidata and data.bibliotheken.nl, the LOD triple store of the KB. The last column shows (the URLs of) the first page of the works. Screenshot Wikidata query service, d.d. 19-05-2021
Reuse - individual highlight images
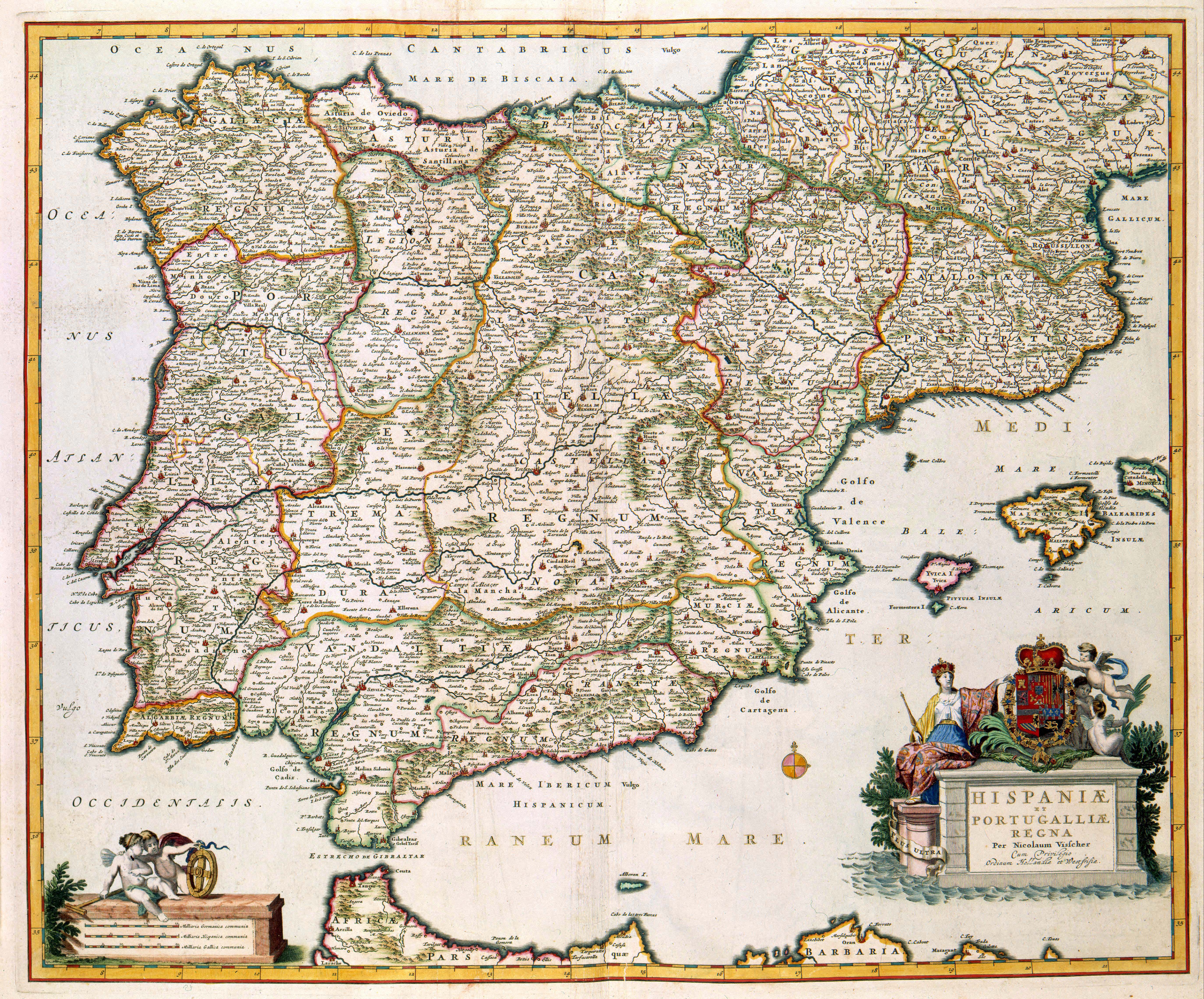
Finally, to wrap up this (long) article, let’s look at an example of reusing individual highlight images. Let’s use the map of the Iberian Peninsula we looked at in the beginning of Part 4.
{kind=link}
50) Programmatically request (meta)data associated with an individual image
Using a Wikimedia Commons API tool created by (the great) Magnus Manske, we can programmatically request (meta)data associated with an individual image in XML, such as
- https://tools.wmflabs.org/magnus-toolserver/commonsapi.php?image=Atlas_Van_der_Hagen-KW1049B12_002-HISPANIAE_ET_PORTUGALIAE_REGNA.jpeg&thumbwidth=234 - returns the URL of a thumbnail of 234px wide
- https://tools.wmflabs.org/magnus-toolserver/commonsapi.php?image=Atlas_Van_der_Hagen-KW1049B12_002-HISPANIAE_ET_PORTUGALIAE_REGNA.jpeg&thumbwidth=234&meta - adds the EXIF data
{kind=link}
{kind=link}
{kind=link}

URLs associated with the map of the Iberian Peninsula as returned by Magnus Manske’s Wikimedia Commons API tool. Note the URL of the thumbnail of 234px wide. Screenshot Wikimedia Commons API tool, d.d. 15-06-2021
We can also query the Commons API directly to retrieve information about an individual image. We use these examples and this imageinfo API documentation for inspiration. For example:
- https://commons.wikimedia.org/w/api.php?action=query&titles=Image%3AAtlas_Van_der_Hagen-KW1049B12_002-HISPANIAE_ET_PORTUGALIAE_REGNA.jpeg&prop=imageinfo&iiprop=url&format=json - returns the direct image URL, the regular file page URL and the permanent file page URL. See also item 41, bullet 2 @ Double page openings.
- https://commons.wikimedia.org/w/api.php?action=query&titles=Image%3AAtlas_Van_der_Hagen-KW1049B12_002-HISPANIAE_ET_PORTUGALIAE_REGNA.jpeg&prop=imageinfo&iiprop=extmetadata&iiextmetadatalanguage=nl&format=json - returns the formatted metadata (ie. with HTML markup) in Dutch
- https://commons.wikimedia.org/w/api.php?action=query&titles=Image%3AAtlas_Van_der_Hagen-KW1049B12_002-HISPANIAE_ET_PORTUGALIAE_REGNA.jpeg&prop=imageinfo&iiprop=metadata&iimetadataversion=latest&format=json - returns the EXIF data
{kind=link}
{kind=link}
{kind=link}
{kind=link}

Comparision of the same Dutch language metadata snippet for the map of the Iberian Peninsula. Top part from the regular file page, bottom part from the Wikimedia Commons API. Screenshots from Wikimedia Commons (top) and its API (bottom), d.d. 15-06-2021
Summary
OK, we could have easily gone to 60+ examples, but that’s it for this fifth and last article. For convenience and overview, let me summarize all the cool new things for KB’s collection highlights we have seen in this article:
38) A SPARQL driven thumbnail gallery of KB highlights.
39) Structured lists of all KB highlights, both simple and more elaborate in JSON and XML.
40) Programatically check for Wikipedia articles about KB highlights in Dutch.
41) Request multiple image URLs from the Wikimedia Commons query API for a specific highlight, both via URL query strings and Python scripts.
42) Readily available bulk image download tools for obtaining hires image URLs and/or the hires images themselves from a specific KB highlight category on Wikimedia Commons.
43) Request highlight information from the Wikidata API in multiple formats, directly from the highlight’s Qnumber.
44) Request full Wikidata items in seven different formats via a Special:EntityData URL, directly from the Qnumber: HTML, JSON, JSON-LD, RDF, NT, TTL or N3 and PHP.
45) Get a structured, machine readable overview of persons and institutions related to KB highlights, such as authors, makers, contributors, publishers, printers, illustrators, translators, owners, collectors etc.
46) Multiple approaches for generating off-Wiki image galleries from the Wikimedia infrastructure, as detailed in the article Reusing the album amicorum Jacob Heyblocq - Image gallery of album contributors.
47) Programmatically retrieve things depicted in images, either via the Wikimedia Commons SPARQL query service, the Wikimedia Commons API or via the Petscan tool.
48) Starting from selected Wikidata biographical identifiers such as the Europeana entity (P7704), extract information from external (non-Wikimedia) databases using their REST APIs.
49) Extract information simultaneously from both Wikidata and external databases using federated SPARQL queries, such as this example.
50) Programmatically request (meta)data associated with an individual image via both the Wikimedia Commons API tool and directly from the Commons API, using these examples and this imageinfo API documentation for inspiration.
Part 6 - Summary of summaries
As a bonus - and for overview - I’ve created a summary of the individual summaries from parts 2, 3, 4 and the one above. See Part 6, Summary for all 50 new cool things in a super handy single list.
About the author

Olaf Janssen is the Wikimedia coordinator of the KB, the national library of the Netherlands. He contributes to
Wikipedia, Wikimedia Commons and Wikidata as User:OlafJanssen
Reusing this article
This text of this article is available under the CC-BY 4.0 license.

Image sources & credits
- Swiss_army_knife_open,_2012-(01) – Joe Loong, CC BY-SA 2.0, via Wikimedia Commons
- Victorinox_Swiss_Army_SwissChamp_XAVT – Dave Taylor from Boulder, CO, CC BY 2.0, via Wikimedia Commons
.jpg){kind=link}
{kind=link}