wikimedia-commons_copyright-templates
| << Back to stories index | >> To the Github repo of this page |
Free to use? Exploring public domain claims in Wikimedia Commons files sourced from Delpher (May 2025)
Olaf Janssen, xx May 2025
This article is also available as PDF.
![]()
![]()
Delpher offers access to millions of digitized pages from Dutch historical newspapers, books, and magazines — a valuable resource frequently used on Wikimedia Commons. In the first part of this data story, we examine how the Wikimedia community has assigned public domain status to Commons files that have been sourced from Delpher.
In the second part, we explore the validity of these claims and assess whether they align with the actual copyright status of the works. We identify common mistakes made by the Wikimedia community when applying public domain templates to files. Finally, we examine whether these errors have resulted in any serious copyright violations.
Key figures and findings
The most important key figures and findings of this story are:
- kf 1
- kf 2
- kf 3
Intro, preamble, and background
Why did I write this article?
Much of the historical content from Delpher falls into the public domain due to its age and can therefore be uploaded to Wikimedia Commons without concern. At the same time, the KB — being the operator of Delpher — has a contractual obligation towards authors and publishers to monitor potential copyright infringements and to prevent them as much as possible, including Delpher content that has been uploaded to Wikimedia Commons by the Wikimedia contributors.
For this reason, the KB wants to gain a better understanding of which newspaper articles, books, magazines and other materials from Delpher have been uploaded to Wikimedia Commons, and how public domain claims to those files have been assigned by the Wikimedia community. In doing so, it is important to emphasize that the KB has absolutely no intention to act as a copyright police force. The goal is to work together with the Wikimedia community to handle copyright matters responsibly, with respect for both creators and users.
What this article aims to do
- Provide a practical case study of how public domain claims are applied in a real-world environment — specifically, how Wikimedia Commons contributors handle copyright claims for files sourced from Delpher.
- Offer insight into the complexity of public domain claims on Wikimedia Commons — even for the relatively simple case where files originate from a single source (Delpher) from a single country (the Netherlands).
- Explore how accurately Wikimedia contributors apply public domain claims, and assess to what extent potential copyright violations may occur — including whether serious violations are present.
- Share a practical data story of how to machine-analyze and visualize copyright claims for files in (subsets of) Wikimedia Commons using data analysis and visualization techniques.
What this article does not aim to do
- Provide a comprehensive overview of all public domain claims on Wikimedia Commons. This article focuses specifically on files sourced from Delpher, which is a manageable subset of the total number of files in Commons.
- Provide a formal and/or detailed legal analysis of every public domain claim for these files — such an approach would be far too deep for the scope of this data story.
- XXXXXXXXX Identify and flag every potential copyright infringement — aside from highlighting a few obvious and illustrative cases mentioned later in this story. XXXXXXXXXXXX (besides the 5 obvious cases mention below)
- Offer recommendations or proposals on how to simplify public domain claims on Wikimedia Commons. This article takes the current public domain landscape “as is,” observing how it functions in practice without suggesting reform.
Who is this article relevant for?
This analysis of public domain template usage on Wikimedia Commons applied to files sourced from Delpher may be of interest to:
- The Wikimedia community – to gain insights into how (accurately) they have implemented public domain copyright templates, especially for Delpher-sourced files.
- The Delpher development team and user community – to better understand how a decentralized, international community of content reusers deals with public domain Delpher-sourced materials in a real-world scenario, i.e. on Wikimedia Commons.
- Other GLAM institutions with collections on Wikimedia Commons – to explore how this Delpher case study could be replicated for their own Wikimedia Commons files, supported by the freely available code, data and documentation shared via this article.
- KB copyright lawyers and the wider legal/copyright community – to see how copyright law and public domain issues play out in a real-world, community-driven environment, and to reflect on the practical implications for heritage institutions like the KB.
- Rights holders, publishers and collective rights organizations – to assess whether there should be reasons for serious concern about large-scale copyright violations by the Wikimedia community (spoiler: our findings suggest there is little to no cause for such concern).
Copyrights templates in Wikimedia Commons
Wikimedia Commons is one of the largest open-access media repositories in the world, used daily by Wikipedia and countless other businesses and projects. To protect the open and reusable nature of its content, strict legal rules must be followed for files that are uploaded to Commons:
1) All uploaded files must either be:
- Out of copyright — meaning they are in the public domain, either passively because copyrights have expired, or because the rights holders have waived any copyrights on the files, actively releasing them into the public domain, for instance by using a CC0 license.
- Freely licensed — under licenses that allow reuse and modification, most commonly CC-BY, CC-BY-SA, or equivalent.
2) These copyright claims must be explicitly and unambiguously added to the file description page. See for instance the public domain claim stated in this portrait made by the Dutch photograhper Toni Arens-Tepe (1883–1947).
.jpg&action=edit§ion=2){kind=link}
.jpg){kind=link}
3) These claims are typically expressed through standardized copyright templates (also known as license tags). These templates are meant to ensure clarity, uniformity and standardization when declaring copyright status of files. Templates on Commons can be recognized by the double curly brackets they are called by, for instance
- {{PD-old-70}} — The file is in the public domain because the creator of the underlying work died more than 70 years ago.
- {{CC-BY-SA-4.0}} — Creative Commons Attribution-ShareAlike 4.0 license.
- {{PD-ineligible}} — The file is in the public domain because it (and/or its underlying work) lacks sufficient originality to be eligible for copyright protection.
The copyright template jungle
But here’s the problem: although the purpose of these templates is to provide a clear and standardized way to declare copyright status, the practical reality is that the license tagging system — built over the years by the international Wikimedia community — has evolved into a very complex beast. The number of different copyright templates in use on Commons is enormous.
To get a sense of this complexity, take a look at this summary of the most common template types or explore this nested overview of several thousands(!) of copyright templates being used on Commons.
Both insiders and outsiders will struggle to find their ways in this system, it can feel like working through a jungle of overlapping licensing options and confusing terminology, undermining the intended simplicity and standardization.
However, this complexity is not entirely surprising. Wikimedia Commons accepts media from any country, any jurisdiction and any historical period, and must therefore be able to handle the copyright rules and exceptions from dozens of legal systems worldwide. The elaborate system is necessary because Wikimedia Commons is a global, evolving platform. Templates are regularly added or updated as contributors find new sources for uploads or as local copyright regulations change.
Zooming in: public domain templates
To somewhat trim down this jungle, we can narrow the scope and look only at public domain templates, used for files that are out of copyright. Yet even within this limited scope, things remain complicated, as the number and variety of such templates is still pretty large.
The general public domain templates page provides an overview of more than 70 templates based on general criteria, not tied to a specific country or source of the work. The complexity becomes more apparent when examining the Category:PD license tags and its subcategories. These include numerous country-specific public domain templates, each reflecting the legal nuances of copyright legislation in the country of origin.
Adding to this complexity is a crucial requirement: Every file on Wikimedia Commons must also include a justification for its public domain status under U.S. law. This requirement arises from the fact that Wikimedia’s servers are located in the United States. Therefore, all hosted content must comply not only with the copyright laws of the country of origin but also with those of the U.S., which can be particularly intricate and often differ substantially from other jurisdictions.
In practice, this means that many Commons files require multiple templates:
- One or more templates describing the copyright status in the country of origin;
- An additional template confirming the file’s public domain status in the United States.
Zooming in further: copyright templates used in Delpher files
For the purposes of this article, we aim to narrow the scope even further. We are interested only in public domain copyright templates used for files sourced from Delpher, the Dutch platform providing access to millions of full-text pages from Dutch historical newspapers, books, and magazines. Delpher is a frequently used resource for illustrating Wikipedia articles and for uploads to Wikimedia Commons.
By limiting our focus to this single source, our dataset and analysis become relatively straightforward: we are primarily dealing with materials from one provider (Delpher) and largely from one country (the Netherlands). Nevertheless, as we will explore below, there remains sufficient complexity to make this investigation both meaningful and nuanced.
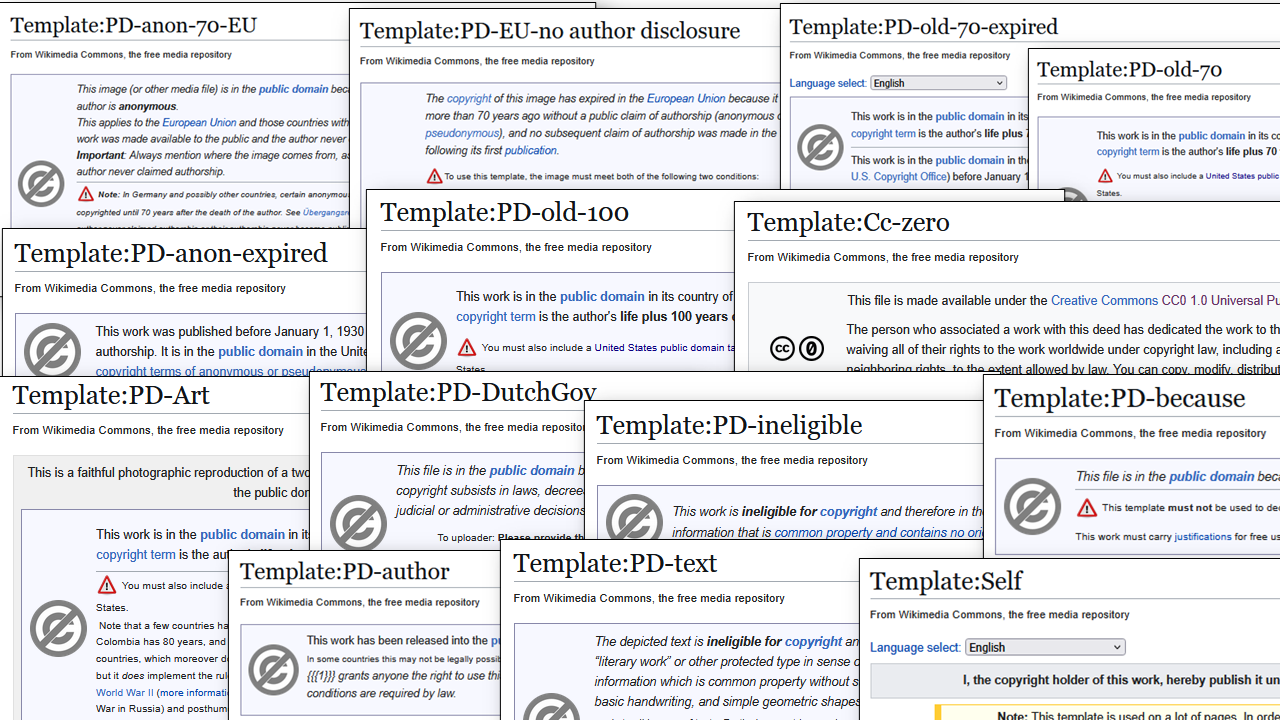
A (non-exhaustive) collage of screenshots of public domain template description pages, as used in Wikimedia Commons files that have been sourced from Delpher (Click to enlarge).
Image license: CC-BY-SA 4.0 / Olaf Janssen, KB national library of the Netherlands.
Creating the dataset
To examine how the Wikimedia community has assigned public domain status to Commons files sourced from Delpher, we first needed a robust and reliable dataset. Let’s look at the steps we took to create it.
This community has been uploading newspaper articles, advertisements, obituaries, book pages, portraits from magazines, and other materials from Delpher (and its predecessor projects) to Wikimedia Commons since March 2008. Because these files were originally scattered across Commons without consistent categorization, the first step was to bring them together into a single, central place: Category:Media from Delpher. This category currently contains just over over 62K files.
{kind=link}
Delpher source template
We added a {{Delpher}} source template to all of these files (example). This is not only to visually and textually communicate that Delpher is the source of these files, but also to automatically include the files into the said category.
{kind=link}

A screenshot of the rendered Delpher source template on Wikimedia Commons.
Excluding scans from the Internet Archive
As you can see in the category, a significant part is filled with files claimed to be uploaded from the Internet Archive, but that find their real origins in Delpher. These are the PDFs with IA ddd …mpeg21 in their titles (example). In total there are 55,761 files from the Internet Archive (d.d. 9 April 2025) that were originally sourced from Delpher.
All of these files are marked with the {{PD-old-70-expired}} copyright template, which means that they are safely in the public domain in the Netherlands (and its predecessors), the rest of the EU and the United States.
Because such a large part - 89.6% of the files - in the Category:Media from Delpher come from the Internet Archive, we decided to exclude all of them from our further analysis. And because they are marked with the exact same copyright template, including them would make our analysis too biased (or skewed) towards these files and templates.
Extracting copyright templates
This left us with 6,496 ‘non-Internet Archive’ files from Delpher. For these files we wanted to extract the associated copyright templates. Assisted by ChatGPT, we developed a (rather monsterous) Python script to extract public domain or public domain-like license templates (e.g., Creative Commons). As this script was not 100% perfect, we needed to do some manual post-processing to clean up the data.
Excluding files without publication/creation dates
As we plan to assess the validity of copyright claims against the actual publication or creation dates of the underlying works, we also designed the script to extract simplified date information. Files that provided no publication or creation dates were excluded from further analysis. We will discuss the date extraction process in more detail in SECTIONXXXXXXXXXXXXXXXXXXX.
Deleting obvious copyright violations
After the extraction of templates and associated dates, we did a preliminary scan to identify obvious instances of copyright infringement, which we wanted to exclude from our dataset. Specifically, we examined content published within the last 70 years (post-1955) that were nonetheless marked as public domain or Creative Commons-licensed. This process led to the identification of four copyvio files for which we subsequently submitted deletion requests to Wikimedia Commons administrators:
- An article from the Dutch newspaper De Telegraaf from 1985, still under copyright, as it was published less than 70 years ago. It cannot have a CC0 license.
- An article from the Dutch newspaper Trouw from 1974. Still under copyright, as it was published less than 70 years ago. We must assume that the copyright is held by the newspaper publisher, unless proven otherwise.
- An article from the Dutch newspaper Algemeen Dagblad from 1966. Still under copyright, as it was published less than 70 years ago. We must assume that the copyright is held by the newspaper publisher, unless proven otherwise. Futhermore, it can not have a CCO license.
- The text Het Binnenhof en Het Vaderland from 1956 by Duco Wilhelm Sickinghe. According to Dutch coppyright law, this article is still under copyright, as the author died in 1983 and the article was published less than 70 years ago. So we must assume that the copyright is still with the (heirs of the) author or with the newspaper publisher, unless proven otherwise. Futhermore, it cannot have a CC-BY license.
{kind=link}
{kind=link}
{kind=link}
_in_dagblad_Het_Binnenhof_en_Het_Vaderland_(1956).jpg){kind=link}
All deletion requests were granted immediately and the files were deleted quickly.
The final dataset
In the end, we were able to retrieve 6,247 distinct files that contained (one or more) copyright templates (6,329 in total), as well as a publication or creation date. This is the dataset used in our further analysis. XXXXX TODO XXXXXXXX
Why are Delpher sourced files in the public domain, according to Wikimedia Commons?
What insights can be gained from this dataset? A useful starting point is to examine the main reasons why files have been classified as public domain by their uploaders.
Grouping templates
To do this, we first grouped the copyright templates according to their underlying rationale for placing files in the public domain. This process resulted in five distinct categories:
-
Copyrights expired because of age: This is the most common reason, because the underlying work is too old to carry copyrights. Its digital reproduction (2D scan, photo) is generally also considered to be in the in the public domain.
Example templates: {{PD-old-70}} or {{PD-old-70-expired}}. -
Copyrights waived or made free: For files that have been released into the public domain or under free licences by their creators or rights holders.
Example templates: {{CC-zero}} or {{CC-BY-SA-4.0}}.
Note: for the readability and flow of this article, we will not make distinctions between the files in this category that have been given CC0(-like) templates and the (very limited number of) files that have been given CC-BY or CC-BY-SA copyright claims. For the purposes of this article, these are all considered (or ‘enforeced’) to be in the public domain. -
Government work, not subject to copyright: For files that are created by government employees in the course of their official duties, which are not subject to copyright protection in many jurisdictions, including the Netherlands and the United States.
Example template: {{PD-DutchGov}} -
Not eligible for copyrights due to lack of sufficient originality: This includes files that are not eligible for copyright protection because they lack sufficient originality, such as simple logos, signatures, or other works that do not meet the threshold for copyrightability.
Example templates: {{PD-ineligible}} or {{PD-textlogo}} -
Other reasons: For files that are in the public domain for other reasons, such as being published before the introduction of copyright laws, or because they are not eligible for copyright protection for other reasons.
Example template: {{PD-because}}.
Visualizing the results
If we break down the data, we see that our 6,247 files are classified into the public domain by 6,329 templates for the following reasons:
| Reason for public domain classification | Number of template uses | Percentage |
|---|---|---|
| Copyrights expired because of age | 6,191 | 97,8% |
| Copyrights waived or made free | 97 | 1,5% |
| Government work, not subject to copyright | 20 | 0,3% |
| Not eligible for copyrights due to lack of sufficient originality | 18 | 0,3% |
| Other reasons | 3 | 0,03% |
| Total | 6,329 | 100% |
These results are also visualized in the donut chart below. For instance, the 6,191 files in the blue sector are in the public domain because the historical newspapers, books and magazines they were sourced from, are too old to carry copyrights. Please note that one file can contain multiple out-of-copyright claims, see this example.
{kind=link}

Quote 1
Quote 2
Section 2.1
Explan which templates have been found

xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx

Section 2.1 - Zooming in on copyrights expired because of age
Next., lets’;s zoom in on the copyright templates that are used for files that are in the public domain because of age. The blue colors. In total theis comprises 24 templates 6191 used in xx distinct files
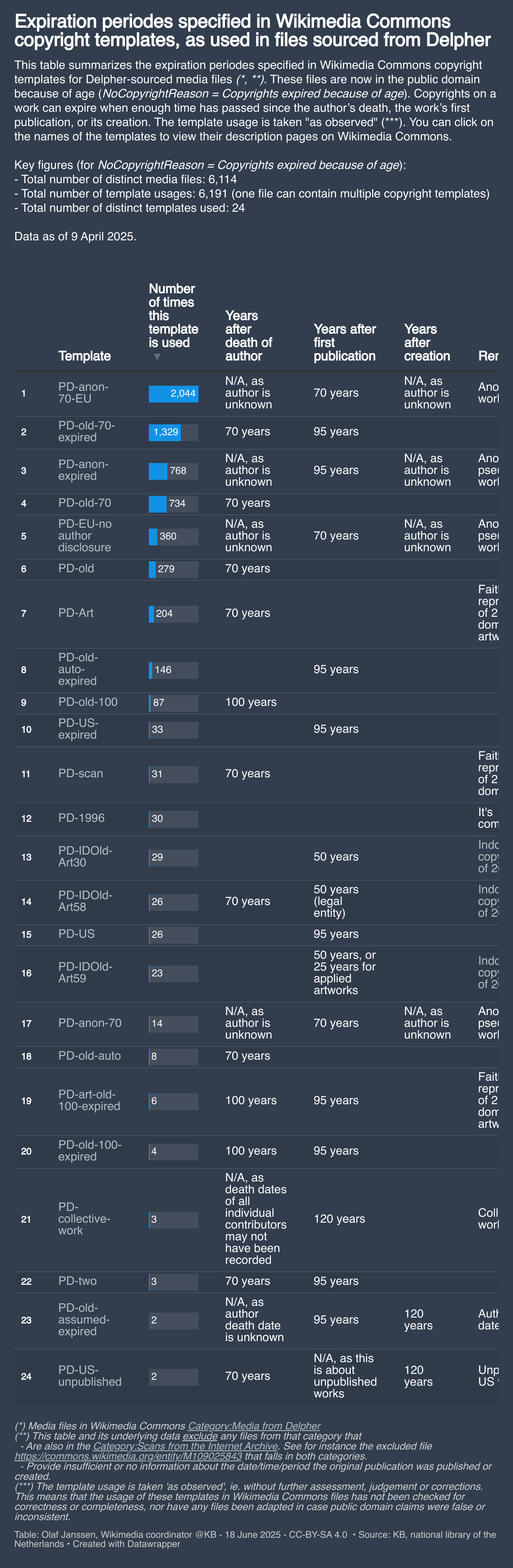
Section 3 Compliance of the community to the copyrights stramtrwents
Are thre any violations of big mistakes?
forthe “pd becauase of age groop” (98% of uses) we will llok at the year in which the orginalwork was published or creaed (column F “DateOfPublicationOrCreation” in the Excel)
- The years of publication or creation have been extrachred from the Wikitext, typically the “Date-field”
- for most fies the date could be extracted as a single year, for instance files taken from newspapers that were published in 1863, 1926 or 1952.
- In case this date was not a single year the latest/most recent year has been taken. For isntance 1920s (–> YYYY) , before 1880 (–> YYYY) or circa 1949(–> YYYY).
{kind=link}
{kind=link}
{kind=link}
Interesting cases to study, in the Excel
- Files classified ““Copyrights waived or made free””
- Fioles from publ;ications 1955 or later that are marked as public domain
Make Datarwapper for trhat https://commons.wikimedia.org/wiki/File:Proclamatie1955-Amigoe.jpg File:Proclamatie1955-Amigoe.jpg M147748690 Klik 1 1955 https://commons.wikimedia.org/wiki/Template:PD-anon-70-EU Klik Copyrights expired because of age https://commons.wikimedia.org/wiki/File:1957_Foto-album_van_burgemeester_P.M.J.S._Cremers%2C_1957_18.jpg File:1957_Foto-album_van_burgemeester_P.M.J.S._Cremers,_1957_18.jpg M150325640 Klik 1 1957 https://commons.wikimedia.org/wiki/Template:Cc-by-4.0 Klik Copyrights waived or made free https://commons.wikimedia.org/wiki/File:Hindeloopen_vlag_1650.svg File:Hindeloopen_vlag_1650.svg M81840054 Klik 1 1957 https://commons.wikimedia.org/wiki/Template:PD-self Klik Copyrights waived or made free https://commons.wikimedia.org/wiki/File:Handtekening_George_van_den_Bergh.jpg File:Handtekening_George_van_den_Bergh.jpg M89816821 Klik 1 1960 https://commons.wikimedia.org/wiki/Template:PD-signature Klik Not eligible for copyrights due to lack of sufficient originality https://commons.wikimedia.org/wiki/File:Expositie_van_18_jonge_Nederlandse_striptekenaars_in_Kunstcentrum_Lijnbaan%2C_1971.jpg File:Expositie_van_18_jonge_Nederlandse_striptekenaars_in_Kunstcentrum_Lijnbaan,_1971.jpg M112239095 Klik 1 1971 https://commons.wikimedia.org/wiki/Template:Cc-zero Klik Copyrights waived or made free https://commons.wikimedia.org/wiki/File:IJ_with_two_acute_accents_in_Staatsblad_van_het_Koninkrijk_der_Nederlanden%2C_no._394%2C_1996%2C_p._17.png File:IJ_with_two_acute_accents_in_Staatsblad_van_het_Koninkrijk_der_Nederlanden,_no._394,_1996,_p._17.png M129412274 Klik 1 1996 https://commons.wikimedia.org/wiki/Template:PD-text Klik Not eligible for copyrights due to lack of sufficient originality
Section 4: Commonmly made mistakes of the community when aplying PD templtes to Delphetr files
Section 5: Recommendactions to the
- Wikimedia community to improve the copyright templates and their usage
- Delpher/ KB team
- KB copyright lawyers
- CBO’s & publishers
Raw data
All data used for the visualisations and analytics in this article is available on Github. You can also download the main Excel file directly.
About the authors


Olaf Janssen is the Wikimedia coördinator of the KB, the national library of the Netherlands. He contributes to Wikipedia, Wikimedia Commons and Wikidata as User:OlafJanssen. ORCID: 0000-0002-9058-9941.
Reusing this article
The text and data visualisations of this article have been released under Creative Commons Attribution CC-BY 4.0 license.

Citation: Janssen, O.D. (2025). ‘xxxxxx. https://doi.org/10.5281/zenodo.xxxx.
Attribution: KB, national library of the Netherlands / Olaf Janssen, CC-BY 4.0
Raw data: CC0, so released into the public domain. You may freely use, adapt, and redistribute it.
Identifiers and URLs of this article
Persistent:
- DOI (Zenodo): https://doi.org/10.5281/zenodo.xxx
- Wikimedia Commons: https://commons.wikimedia.org/entity/xxxx
Non-persistent: